
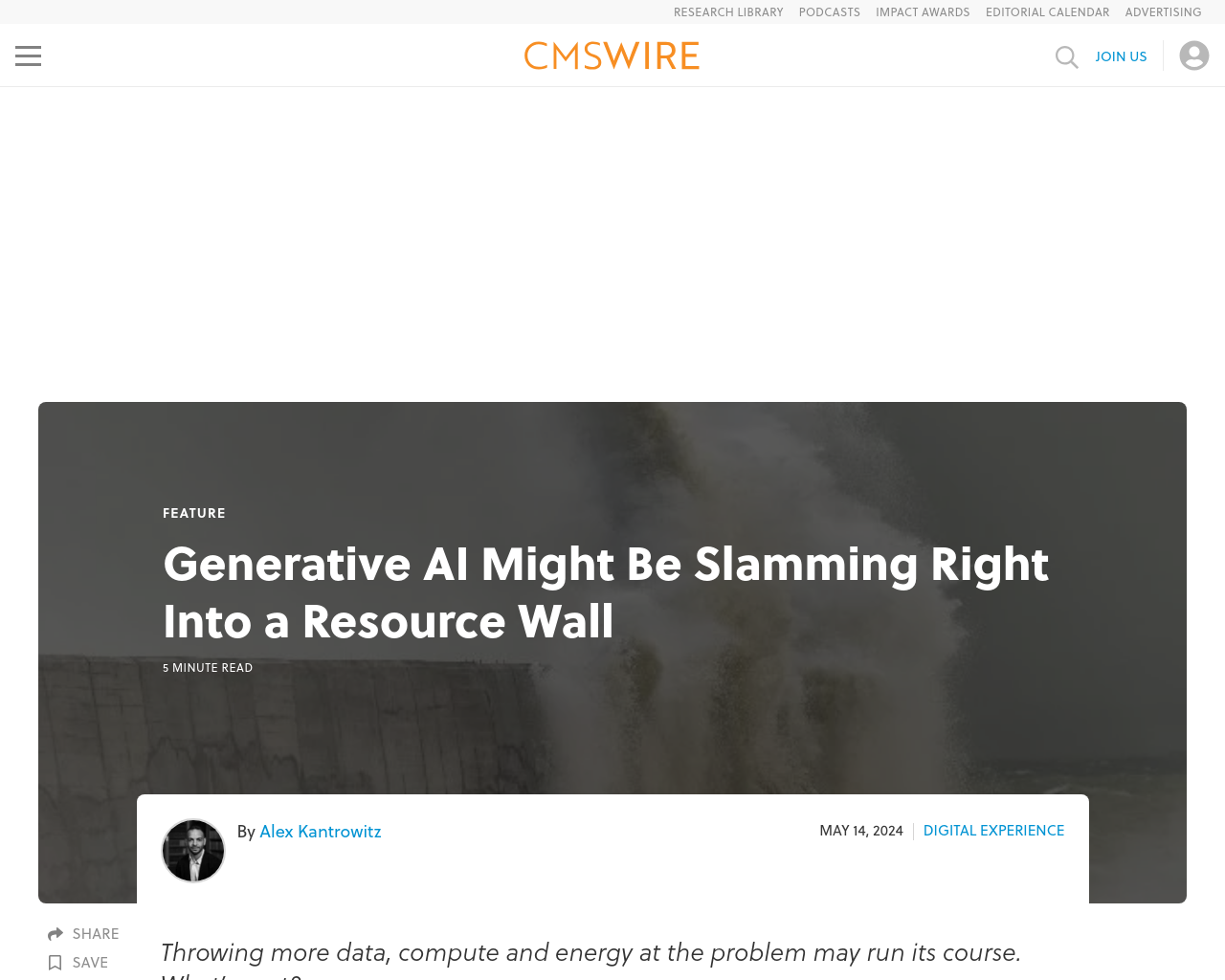
技術記事の要約
- Metaは新しいLlama 3モデルを前モデルの10倍のデータと100倍の計算能力を使って訓練。
- チップ不足の中、高価なGPUを使用し、出版社の買収も検討したほどデータ需要が高い。
- 大規模言語モデル(LLM)の拡張性には限界が見え、効率的な訓練方法や専用ハードウェアの開発が必要。
- AmazonのSwami Sivasubramanianは、新しいアーキテクチャが将来のモデルのスケール方法を変えると述べている。
- AIによる合成データの使用が、モデル訓練において重要な役割を果たしている。
- 専用のAIチップの開発が進んでおり、NVIDIA GPUよりも効率的な訓練が可能に。
- エネルギー消費は大きな制約であり、将来的には巨大なエネルギーを必要とする可能性がある。
個人の感想
LLMの進化は著しいが、その持続可能性には疑問が残る。データや計算能力の増加に頼るだけでなく、新しい技術や方法論の開発が急務であると感じる。特にエネルギー消費の問題は、今後の開発において重要な障壁となり得る。技術の進化だけでなく、環境への配慮も同時に考えるべき時代になっている。