
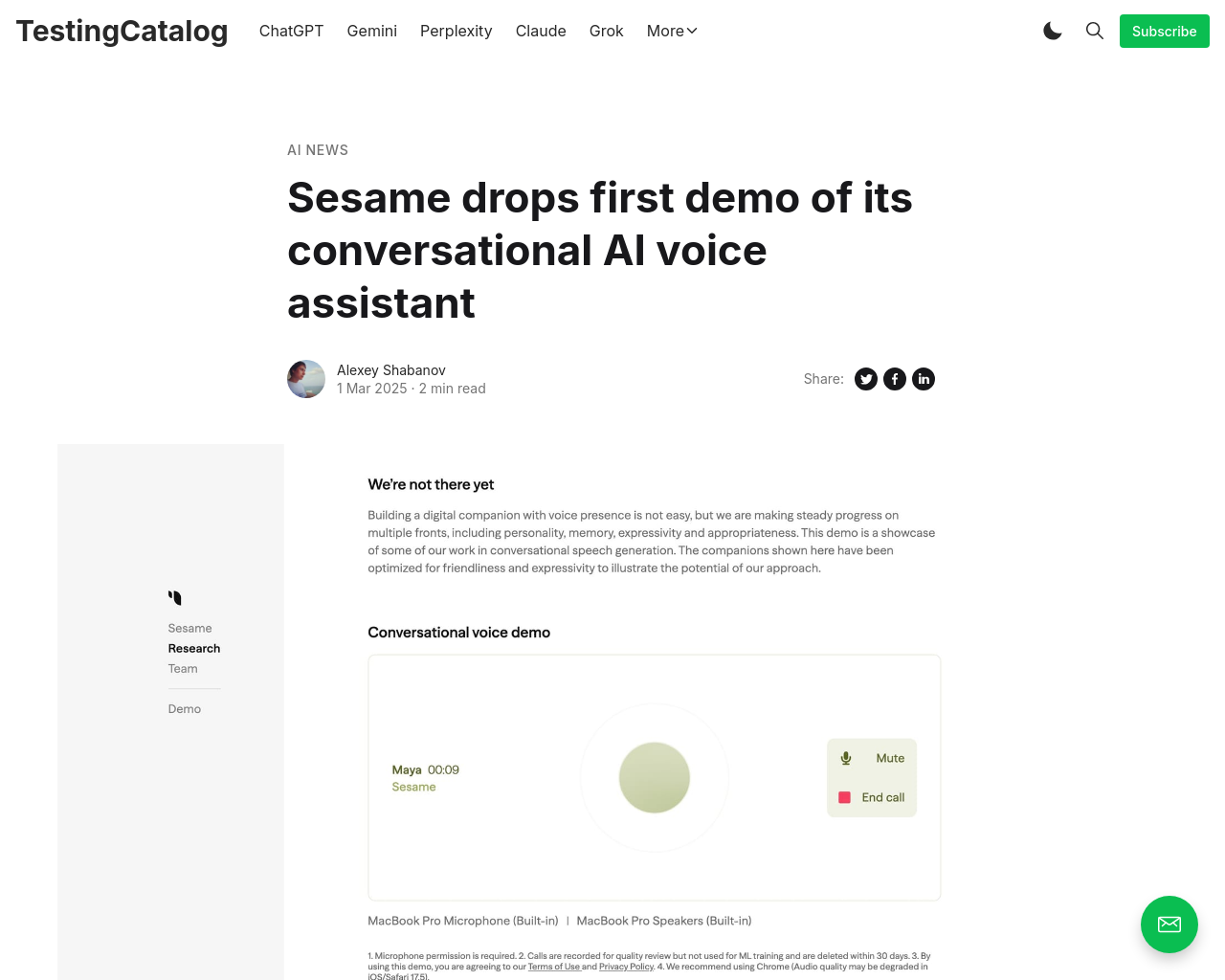
要約:
- 2025年2月27日、Sesameは会話型音声技術の最新研究を発表。
- 目標は、デジタルアシスタントとのインタラクションを感情的に共感できるようにする「声の存在」を実現すること。
- Conversational Speech Model(CSM)は、テキストと音声コンテキストを統合し、会話の歴史、トーン、リズムに適応するスピーチを生成する新しいアプローチ。
- CSMの性能評価には、音声生成における新しいベンチマークが導入され、モデルの能力を評価。
- Sesameは、20以上の言語への対応を追加し、会話のターンテイキングとペース調整をシームレスに管理するデュプレックスモデルの開発に焦点を当てる予定。
- SesameはApache 2.0ライセンスの下で研究の主要部分をオープンソース化することを意図。
感想:
Sesameの取り組みは、会話型AIの進歩において重要な位置を占めている。CSMの開発により、人間らしいデジタルインタラクションに対する技術的課題とユーザーの期待に応えている。特に、感情的なニュアンスや会話の流れを理解し、適切に応答するAIコンパニオンの開発は、今後の技術革新に期待が高まる。