
- DeepSeekが主張する大規模言語モデル(LLM)の訓練速度と効率は、シリコンバレーにとって現実的な課題である
- アリババが新しいフロンティアモデル「Qwen 2.5 Max」を発表し、DeepSeekのV3を凌駕し、アメリカのトップモデルを打ち負かすと主張
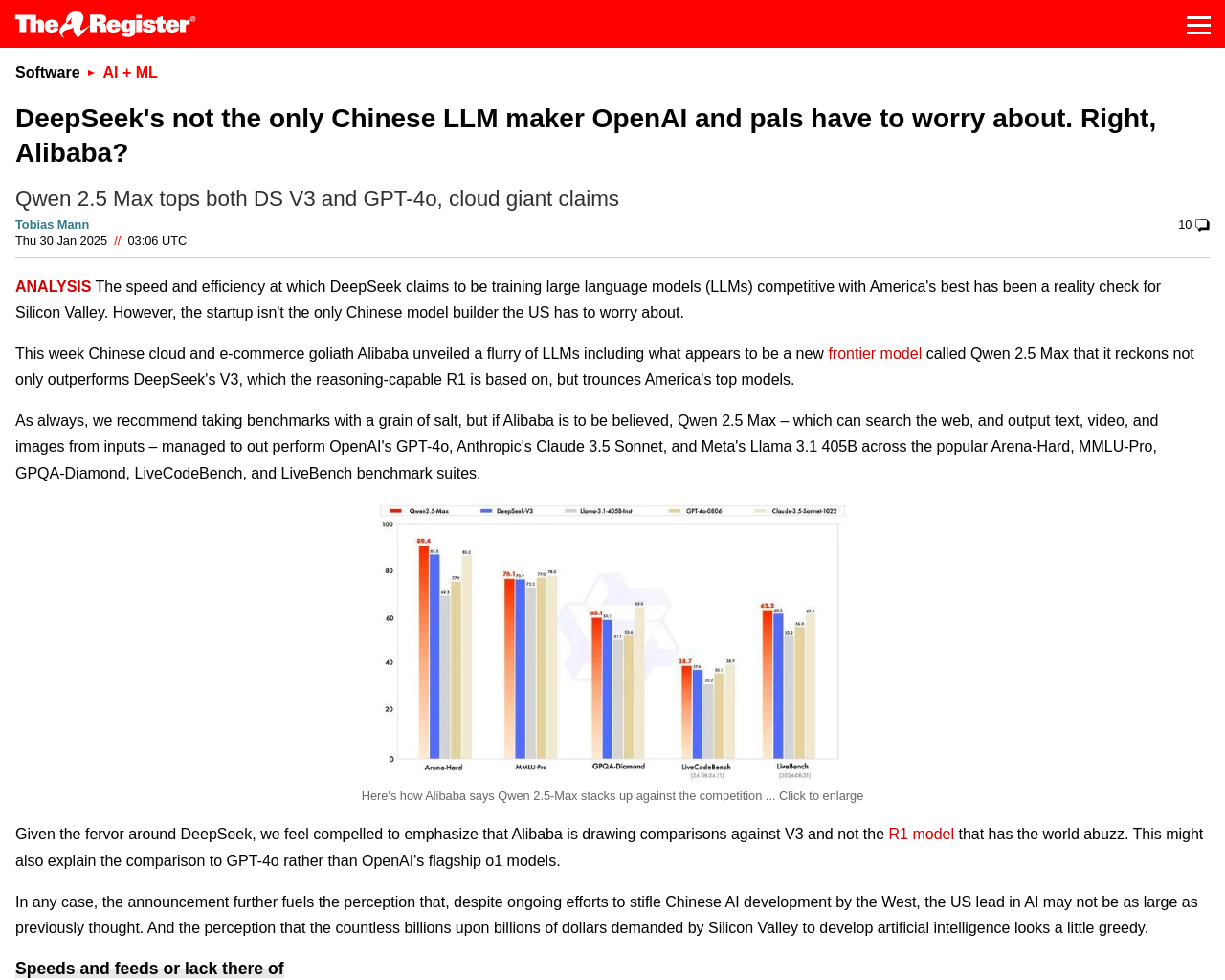
- Qwen 2.5 Maxは、OpenAIのGPT-4o、AnthropicのClaude 3.5 Sonnet、MetaのLlama 3.1 405Bをアリーナハード、MMLUプロ、GPQAダイヤモンド、LiveCodeBench、LiveBenchのベンチマークスイートで凌駕
- モデルの性能、APIアクセス、Webベースのチャットボットに加えて、アリババのQwenチームは最新のモデルリリースについてほとんど情報を公開していない
- Qwen 2.5 MaxはMoEモデルであり、20兆トークンのコーパスで訓練され、人間のフィードバックからの監督された微調整と強化学習を経てさらに洗練された
アリババのQwen 2.5 Maxは、高性能でありながらコストが低い可能性があるが、詳細が不透明であり、性能を評価することが困難である。アリババが続々とリリースしている新しいLLMモデルは、AI開発の世界に革新をもたらす可能性があるが、情報の秘匿やコストとのバランスが重要である。
元記事: https://www.theregister.com/AMP/2025/01/30/alibaba_qwen_ai/