
- AIチューターを駆動する言語モデルを開発
- 複雑なトピックの説明、記事の要約、個人向けクイズ作成が可能
- 従来の評価方法でテストした結果が現実のユーザーのニーズと乖離
- 新しいアプローチ:別の言語モデルを使用してチューターの出力を評価
- AIの真の能力を明確にする方法は?
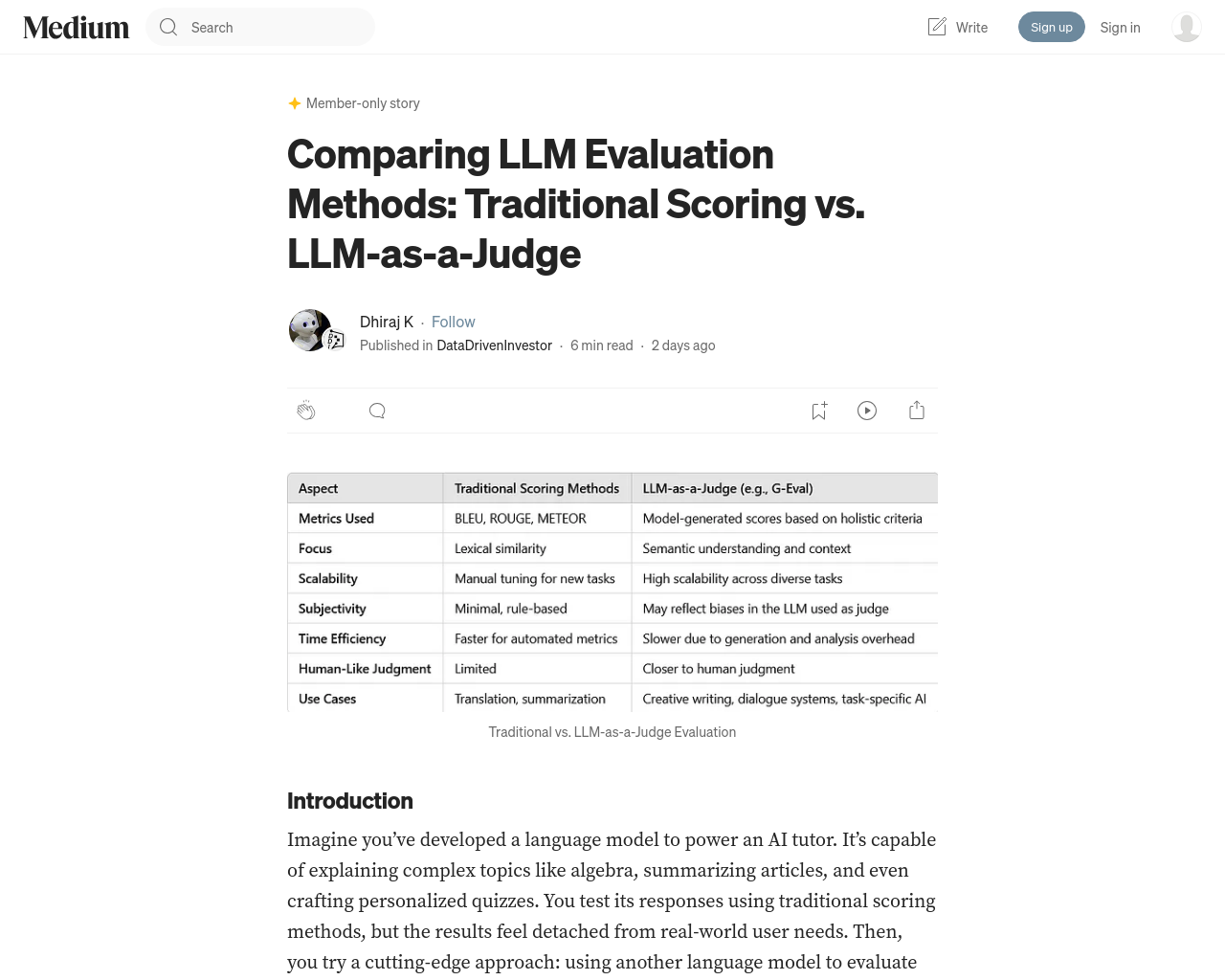
- 言語モデルの評価方法の進化
- 従来のBLEUやROUGEなどのスコアリングメトリクスからLLMを審査員として使用する現代的な手法へ
- NLPの初期には翻訳や要約などの単純なタスク向けの伝統的メトリクスが主流
- 複雑なタスクになるほどニュアンスや創造性、連貫性、事実の正確性を捉えるのが難しい
- AI自体を使用する概念の登場
AI開発者が直面する分岐点。言語モデルが複雑化するにつれ、その有効性を評価する方法も進化している。伝統的なスコアリングメトリクスからLLMを審査員として使用する手法まで、各アプローチには独自の利点と課題がある。NLPの初期では、簡単なタスク向けに設計された伝統的メトリクスが評価に重点が置かれていたが、タスクが複雑化するにつれ、これらのメトリクスでは創造性、連貫性、事実の正確性など微妙な側面を捉えるのに失敗することがよくあった。AIそのものを使用するという概念が登場した。