
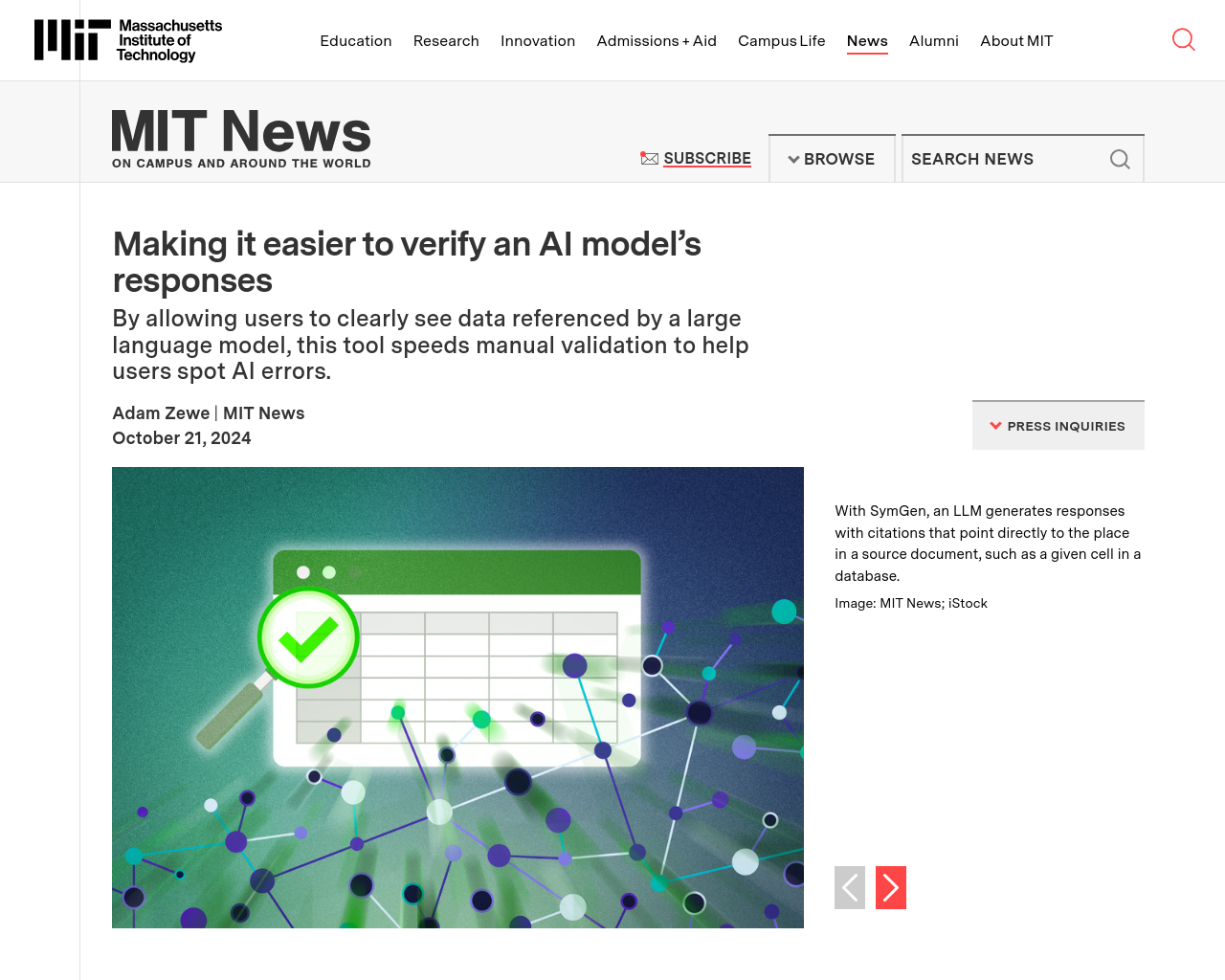
- 大規模言語モデルは完璧ではなく、時々間違った情報を生成することがある
- MITの研究者たちは、人間検証者がLLMの応答を迅速に検証できるよう支援するユーザーフレンドリーシステム「SymGen」を作成
- SymGenは検証時間を約20%短縮し、人々がLLMのエラーを特定するのに役立つ
- SymGenは構造化された形式のソースデータを必要とし、現在は表形式のデータのみに対応
- 将来的には、SymGenを任意のテキストや他の形式のデータに対応させ、AI生成の法的文書要約などを検証する予定
この記事では、大規模言語モデルの応答検証における問題とその解決策であるSymGenについて紹介されています。SymGenは人間検証者がLLMの応答を迅速に検証できるよう支援するシステムであり、検証時間の短縮やエラー特定の手助けとなる可能性があります。しかし、現時点では構造化されたソースデータが必要であり、将来的には他の形式のデータにも対応することが目指されています。
元記事: https://news.mit.edu/2024/making-it-easier-verify-ai-models-responses-1021