
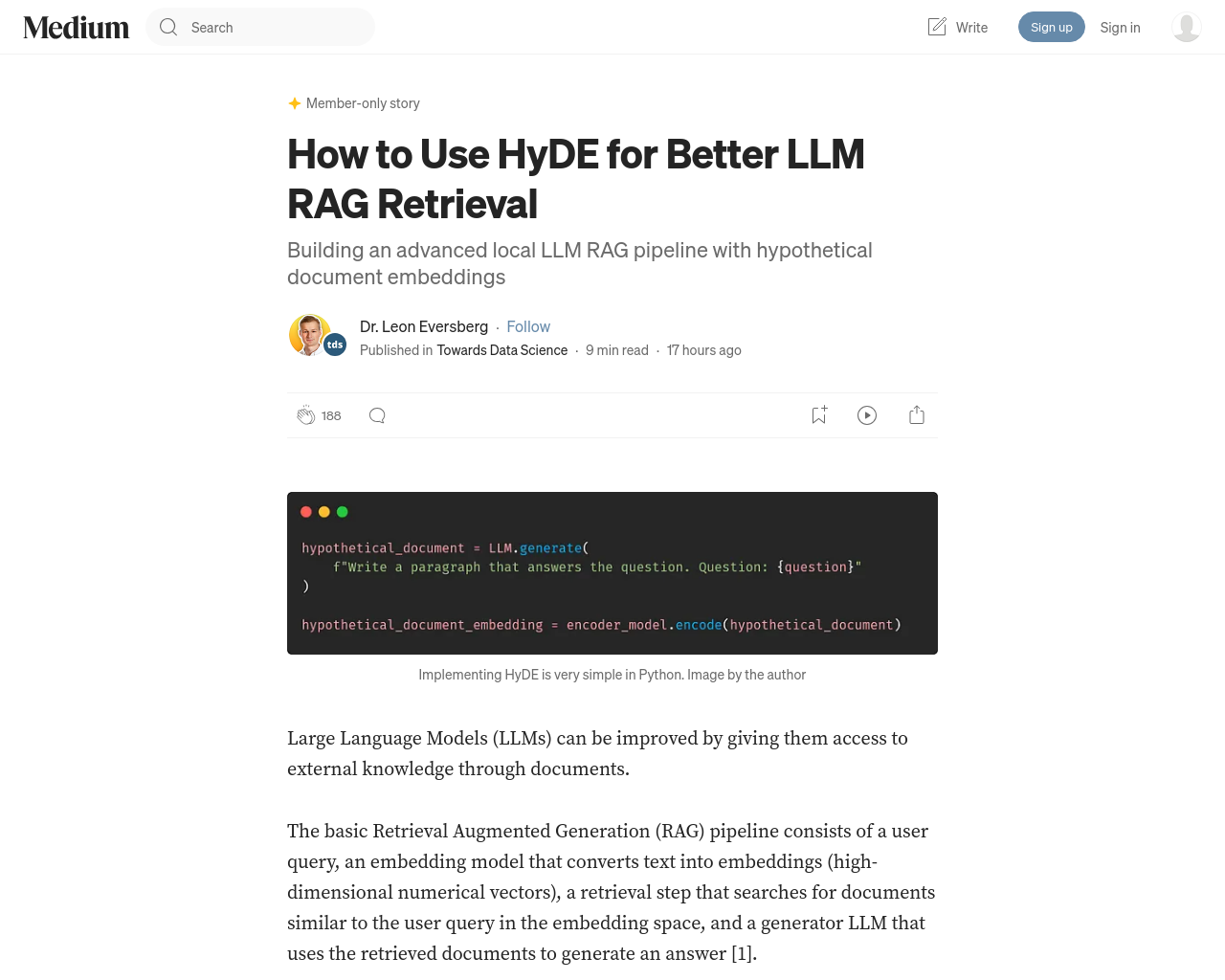
- 大規模言語モデル(LLM)は、外部の文書にアクセスさせることで改善できる。
- 基本的なRetrieval Augmented Generation(RAG)パイプラインには、ユーザークエリ、テキストを埋め込み(高次元数値ベクトル)に変換する埋め込みモデル、埋め込み空間でユーザークエリに類似した文書を検索する検索ステップ、検索された文書を使用して回答を生成するジェネレータLLMが含まれる。
- RAG検索部分が重要であり、リトリーバが文書コーパス内で正しい文書を見つけられない場合、LLMは確かな回答を生成する機会がない。
- 検索ステップの問題は、ユーザークエリが非常に短い質問であり、文法、スペル、句読法が不完全であり、対応する文書は求めている情報を含むよく書かれた長い文章であることが挙げられる。
- HyDEは、ユーザーの質問を変換することでRAG検索ステップを改善する提案された技術である。
提案された技術HyDEは、RAG検索ステップを向上させるために有効な手法であると述べている。リトリーバが正しい文書を見つけられないと、LLMは適切な回答を生成することができないため、ユーザークエリと文書の不一致を解消するための重要性が強調されている。
元記事: https://towardsdatascience.com/how-to-use-hyde-for-better-llm-rag-retrieval-a0aa5d0e23e8