
- 技術の進歩により、処理能力が向上することが一般的に期待されています。
- 改良されたソフトウェアを使用することで、不適切なハードウェア上で動作するものを実行することも可能。
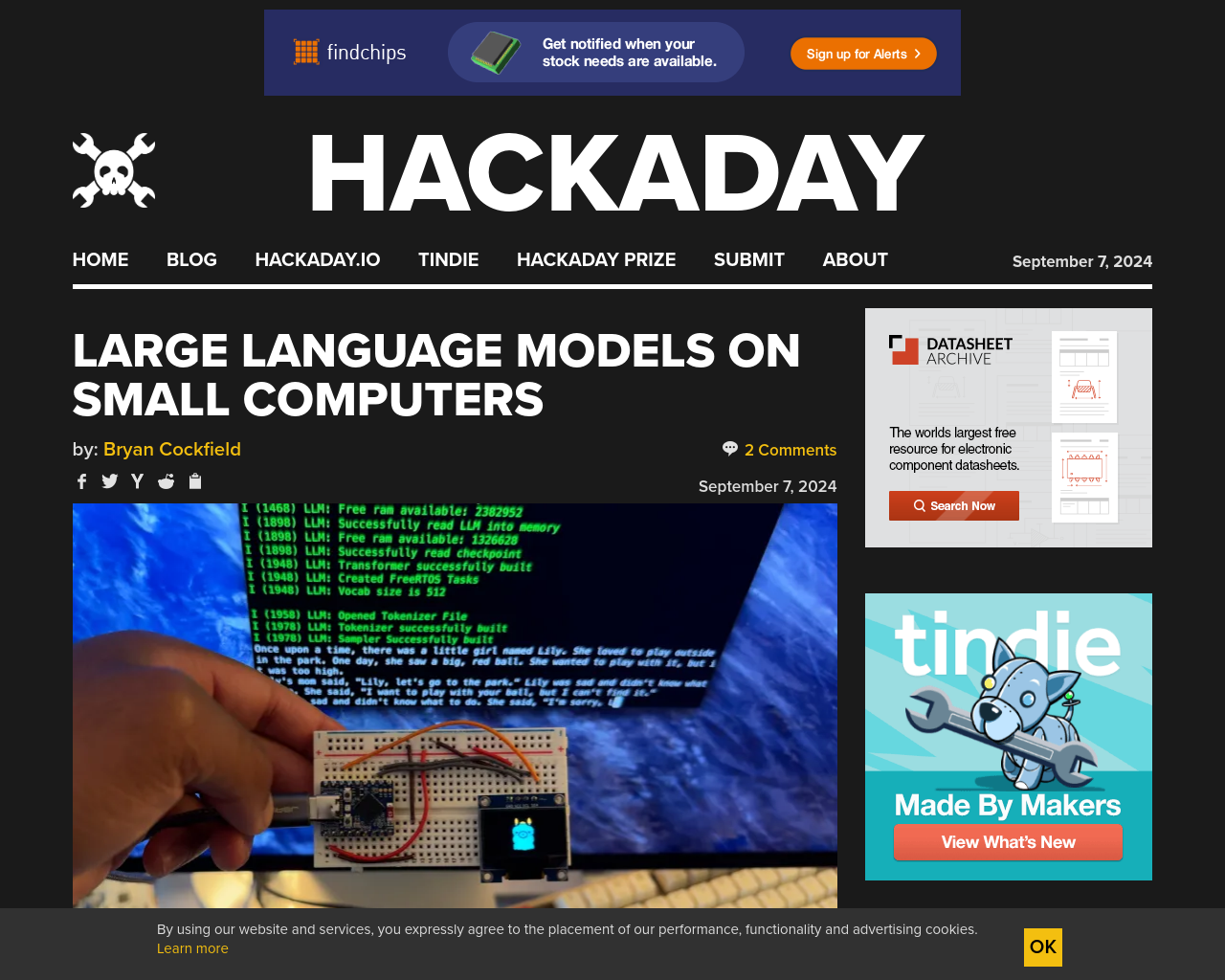
- 大規模言語モデル(LLM)のデータトレーニングに関する課題に対し、[DaveBben]は逆にスケーリングダウンを試みています。
- LLMをESP32などの小さなコンピュータで実行することで、処理能力の向上が可能。
- [DaveBben]が実験に用いたESP32-S3FH4R2は、1 MBのRAMが必要であり、240 MHzのCPUクロック速度を実現。
考え:小さなコンピュータで大規模言語モデルを実行する試みは興味深いです。ESP32が限られたリソースでこのような処理を行うことが可能であることは印象的です。将来的には、より多くのリソースを割り当てることで、自己ホスト型の大規模言語モデルを使用する可能性があると考えられます。
元記事: https://hackaday.com/2024/09/07/large-language-models-on-small-computers/