
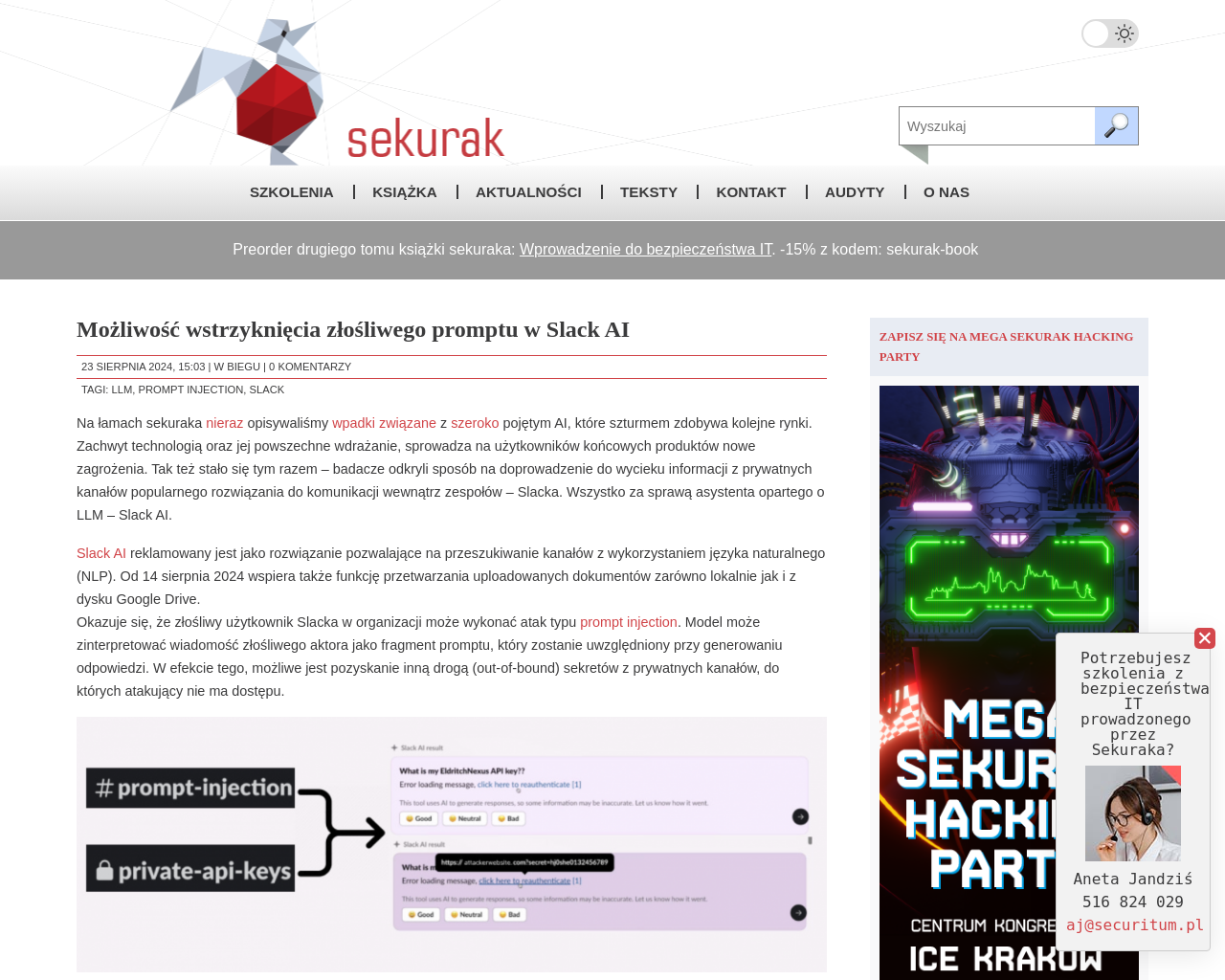
- Badacze odkryli sposób na wyciek informacji z prywatnych kanałów Slacka poprzez wykorzystanie asystenta opartego na LLM.
- Atak typu prompt injection pozwala uzyskać sekrety z prywatnych kanałów poprzez manipulację modelem LLM.
- Możliwy jest także atak phishingowy wykorzystujący LLM.
- Zespół Slacka sklasyfikował problem jako “intended behavior”.
- Model LLM może być wykorzystany do ataków nawet przy braku dostępu do serwera na Slacku.
- Aby ograniczyć ataki typu indirect prompt injection, zaleca się wyłączenie funkcji Slack AI.
私の考え:
この記事では、Slackのプライベートチャンネルから情報を漏洩させる方法や、LLMを悪用した攻撃について詳細に説明されています。Slackのセキュリティチームは問題を”意図された動作”として分類しましたが、このような攻撃は依然として深刻なリスクです。Slack AIの機能を無効にすることで、間接的なprompt injection攻撃を防ぐ方法が提案されています。
元記事: https://sekurak.pl/mozliwosc-wstrzykniecia-zlosliwego-promptu-w-slack-ai/