
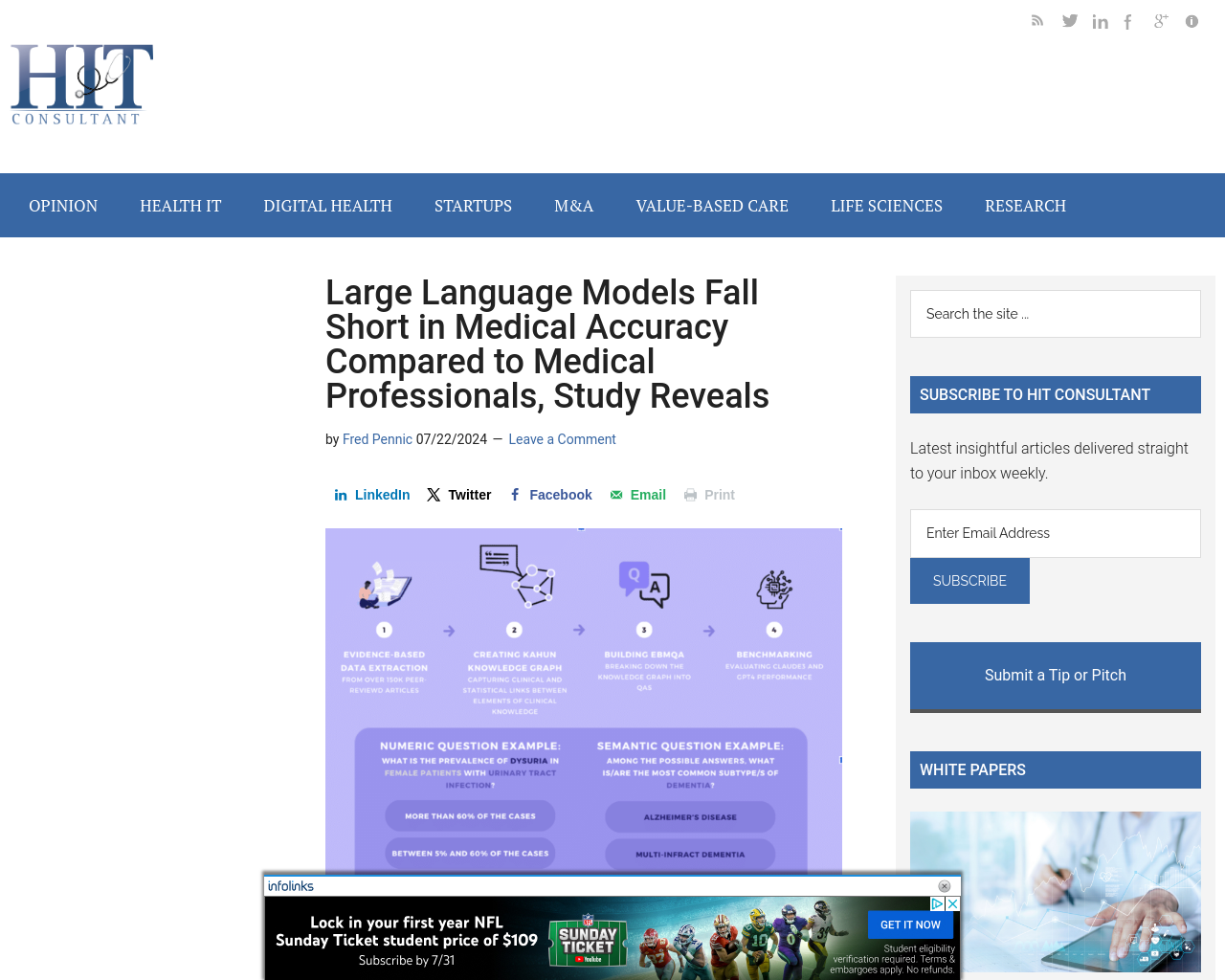
- Kahun社は、臨床AIを専門とする企業であり、人気のある大規模言語モデル(LLM)の医療能力を人間の専門家と比較した新しい研究を発表
- 現在のLLMの限界が臨床判断に信頼性のある情報を提供することにおける制限を明らかにした研究結果が示された
この研究は、現在のLLMの臨床設定における限界を以下の理由により強調している:
- 医師が、臨床診療において生成的AIモデルを使用することへの懸念と関連する。医師たちは、信頼できる医学情報に基づいて訓練されたモデルの必要性と現行技術の限界を理解する重要性を強調している
- LLMは有望であるが、臨床設定における正確さと信頼性を確保するためにはさらなる開発が必要である。一方で、Kahunなどのソリューションは、医療へのAI統合においてより安全で信頼性のある道筋を提供する
「Claude3がGPT-4よりも優れていることが興味深いことでしたが、当社の研究は、一般用途のLLMが日々の医師が遭遇する医学的質問を解釈し分析する点で医療専門家に敵わないことを示しています。ただし、これらの結果は、LLMが臨床的な質問に使用できないことを意味するわけではありません。生成的AIがそのようなタスクを遂行するために潜在能力に達するためには、これらのモデルは確認済みおよびドメイン固有のソースをデータに組み込む必要があります」と、KahunのCEO兼共同創業者であるMichal Tzuchman Katz博士は述べています。 「私たちは、医師が医学的決定を支援するために不可欠な透明性と証拠を提供するソリューションを通じて、研究を通じて医療分野のAIの進歩に貢献し続けることに興奮しています」