
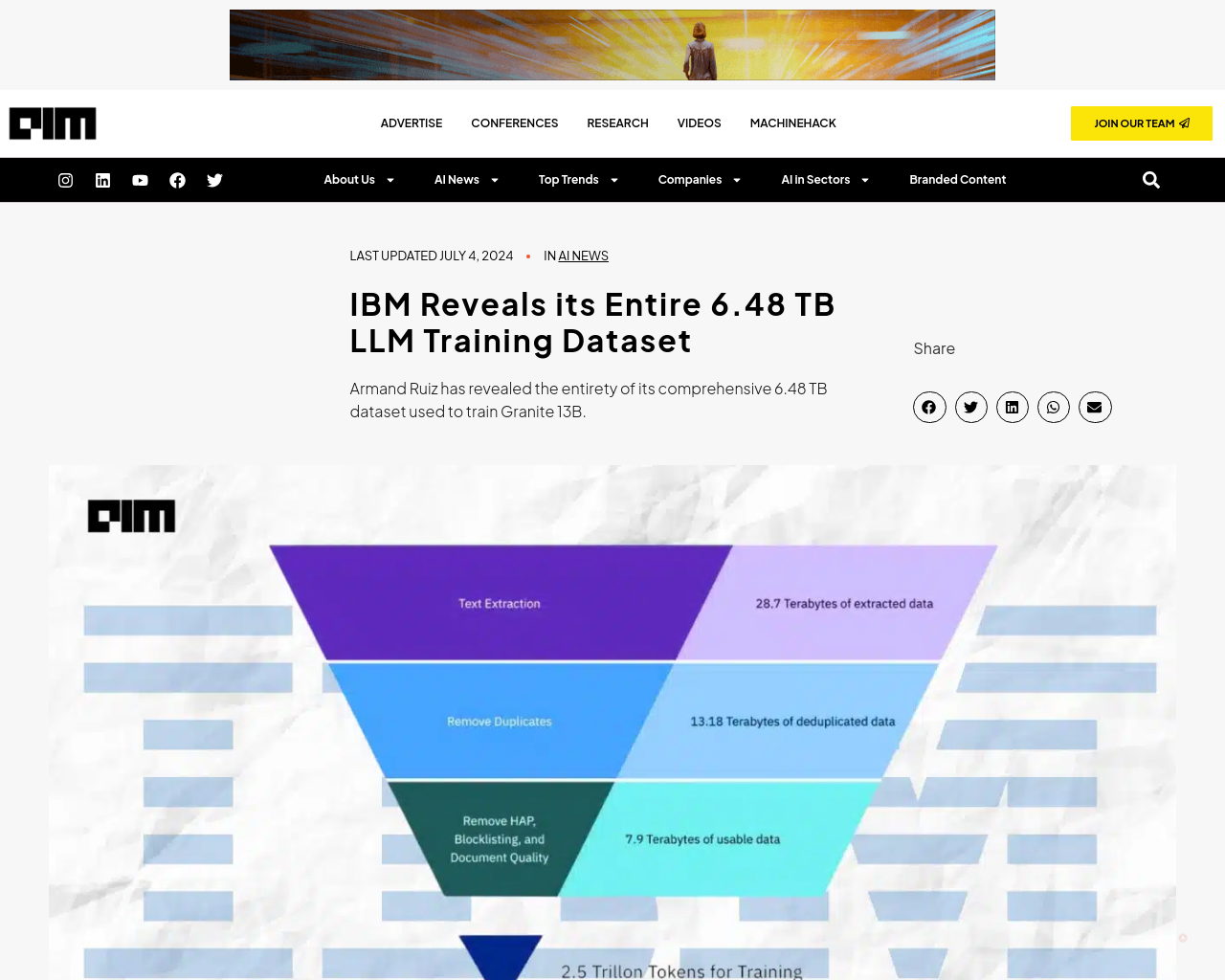
5月、IBMは企業向けに最適なGranite 13B LLMをオープンソース化しました。
Armand Ruiz氏、IBMのAIプラットフォームのVPは、Granite 13Bのトレーニングに使用される包括的な6.48 TBデータセットを公開しました。
- データセットは厳密な前処理を経て、2.07 TBに縮小され、68%の削減が実現されました。
- Ruiz氏は、このステップが企業向けの高品質で偏りのない、倫理的かつ合法的なデータセットを確保するために不可欠であると強調しました。
データセットは、以下のソースから入念にキュレーションされました:
- テキスト抽出
- 重複排除
- 言語識別
- 文の分割
- 憎悪、虐待、卑猥なアノテーション
- 文書品質アノテーション
- URLブロックリストアノテーション
- フィルタリング
- トークン化
これらのステップは、定義された閾値に基づいてのアノテーションとフィルタリングを含み、最終的なデータセットがモデルトレーニングに最適な品質であることを確保しました。
IBMはGraniteコードモデルの4つのバリエーションをリリースしました。これらのモデルは、3から34兆のパラメータを持ち、他の類似モデルであるCode LlamaやLlama 3を多くのタスクで上回っています。
LeetCodeは主に選択ではなく除外を意図していましたが、これがエンジニアリングにおける否定的なトレンドを生み出しています。
Cypher 2024が米国に拡大し、AI革新のギャップを埋め、企業AI導入の課題に取り組んでいる方法をご覧ください。
AIM India#280, 2nd floor, 5th Main, 15 A cross, Sector 6, HSR layout Bengaluru, Karnataka 560102
AIM Americas99 South Almaden Blvd. Suite 600 San Jose California 95113 USA
© Analytics India Magazine Pvt Ltd & AIM Media House LLC 2024
この記事では、IBMがGranite 13B LLMをオープンソース化し、そのトレーニングに使用されるデータセットの重要性について詳しく説明しています。データセットが高品質であり、企業向けに適したものであるために行われた厳密な前処理の過程や、モデルトレーニングのための最終的なデータセットの品質が確保されるための取り組みが強調されています。また、IBMがリリースしたGraniteコードモデルについても触れられており、他のモデルを上回る性能を示していることが述べられています。
元記事: https://analyticsindiamag.com/ibm-reveals-its-entire-6-48-tb-llm-training-dataset/