
要約:
- Large Language Models(LLMs)は、高い精度で多様なタスクを実行できるため、自然言語処理でますます重要になっている。
- LLMsのファインチューニングには、多くのパラメータの調整が必要であり、計算リソースとメモリを消費する。
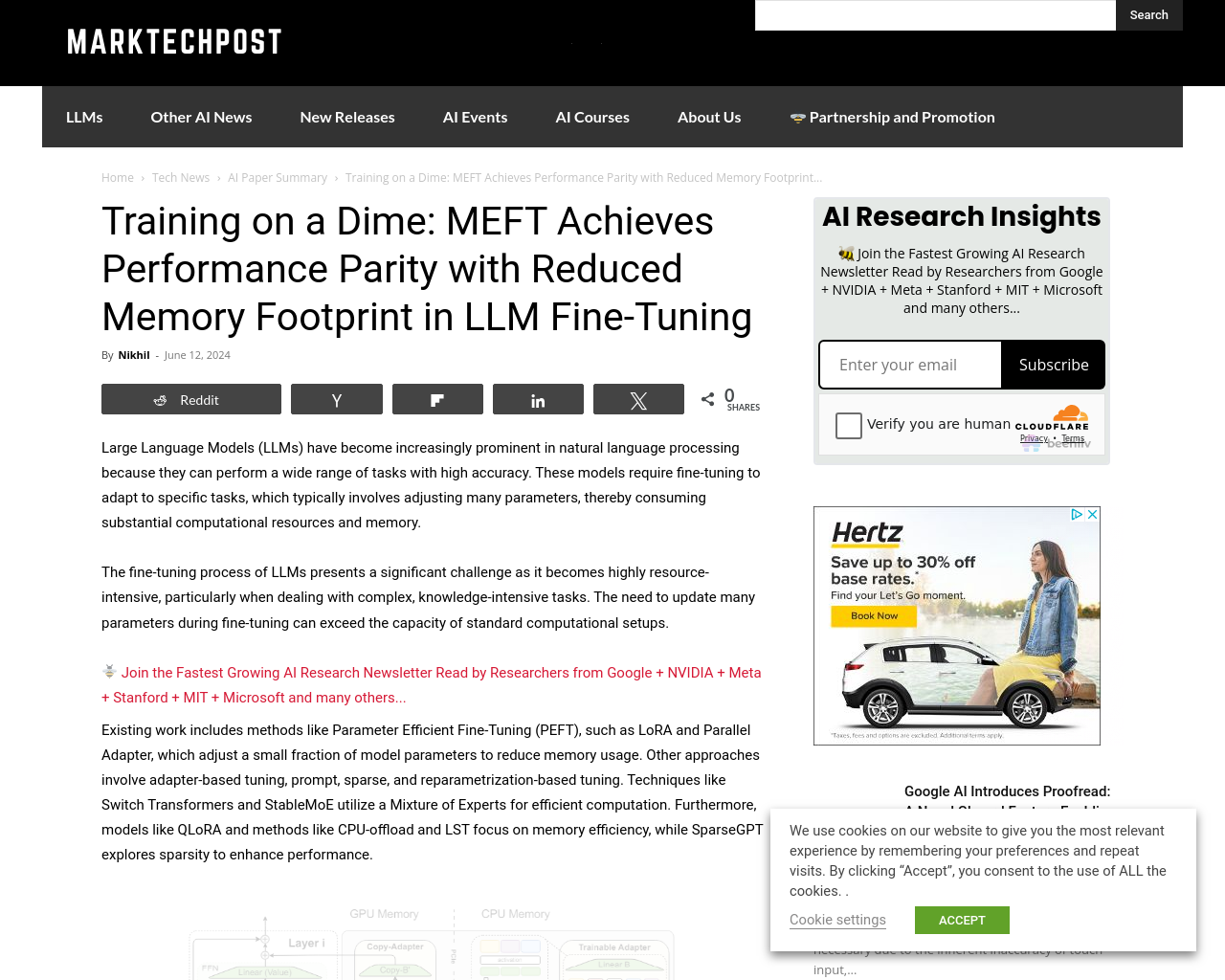
- MEFTは、Feed-Forward Networks(FFNs)内の活性化スパース性を活用し、CPUメモリの大容量を利用することで、メモリ効率の良いファインチューニング手法である。
- MEFTはGPUメモリ使用量を50%削減し、LLaMA-7BとMistral-7Bにおいて優れた性能を示し、リソース制約下で効率的なLLMsのファインチューニングを可能にする。
考察:
MEFTは、活性化スパース性とMixture of Experts(MoE)を活用することで、メモリ使用量と計算要求を削減し、リソース制約下でのLLMsのファインチューニングに効果的な手法である。その効率的なリソース利用により、MEFTは限られたGPU容量内でより多くのトレーニング可能なパラメータを収容できる。このイノベーションは、モデルのファインチューニングにおける重要なスケーラビリティの問題に対処し、より効率的でスケーラブルなアプローチを提供している。研究結果から、MEFTはフルモデルのファインチューニングと同等の結果を達成できることが示唆され、自然言語処理における重要な進展である。