
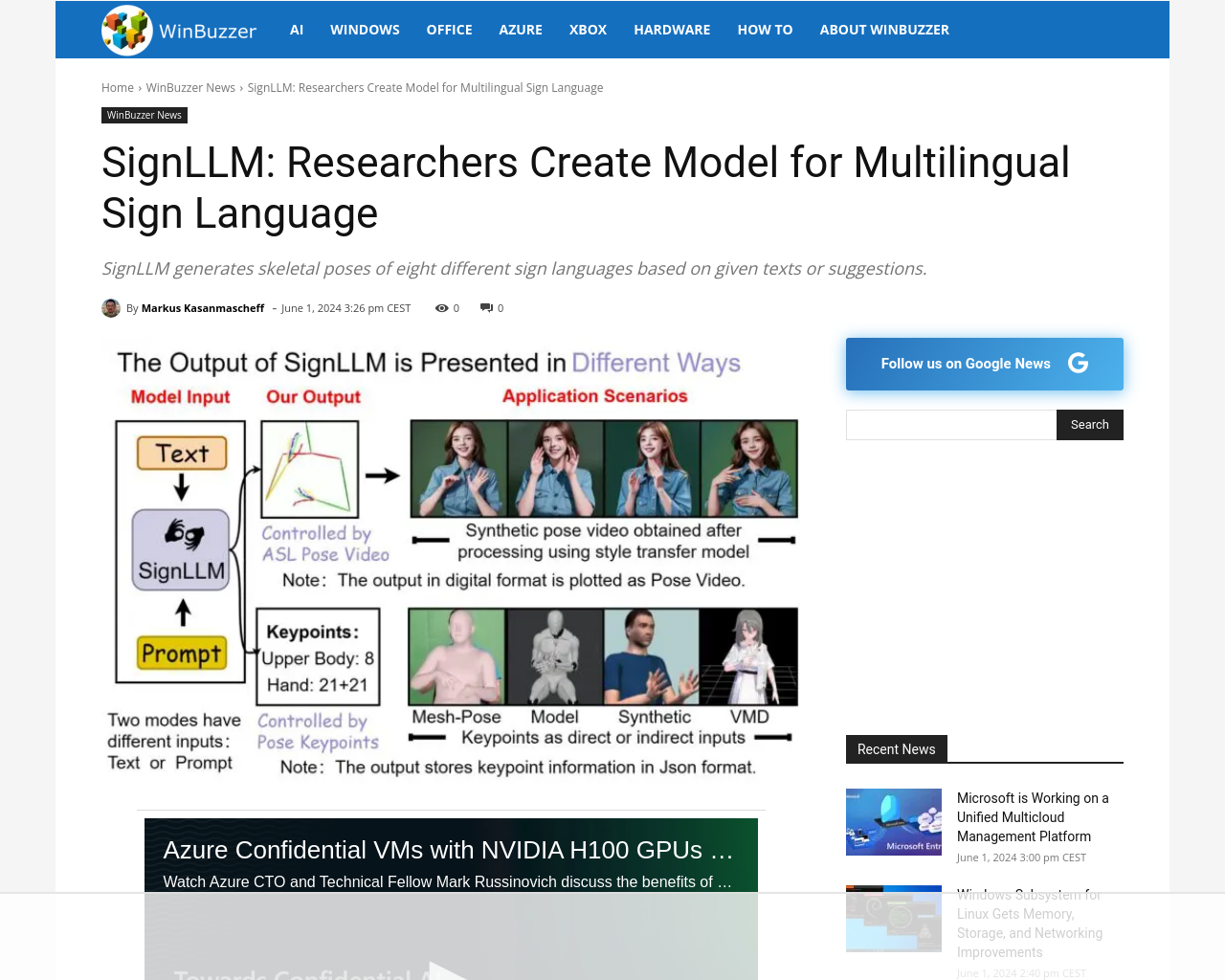
- SignLLMは、与えられたテキストや提案に基づいて、8つの異なる手話の骨格ポーズを生成する。
- SignLLMは、テキスト入力から手話ジェスチャーを生成する包括的な多言語モデルであり、複数の手話の認識と生成における新たな基準を設定している。
- 従来の手話生成方法は、テキストをグロスに変換し(ジェスチャーの表現言語)、その後ビデオを作成して手話の動きをシミュレートすることを含む。
- 過去10年間、ドイツ手話(GSL)データセットPHOENIX14Tなどのデータセットは、手話生成(SLP)、手話認識(SLR)、手話翻訳(SLT)のために扱いにくかった。
- 研究者たちはPrompt2Signデータセットを作成し、8つの異なる手話をカバーするように設計された。
- OpenPoseを利用して、ビデオフレームデータの標準化を行い、冗長性を減らし、シーケンス間およびテキスト間モデルのトレーニングを簡素化している。
- 研究者たちはPrompt2SignデータセットをベースにSignLLMを開発し、8つの異なる手話に基づいて骨格ポーズを生成する大規模な多言語SLPモデルを提供している。
- SignLLMの動作モードには、複数の手話を同時に処理するためにエンコーダーデコーダーグループを動的に組み込むMLSFと、静的エンコーダーデコーダーペアの作成をサポートするPrompt2LangGlossモジュールがある。
SignLLMは、テキストに基づいて8つの異なる手話の骨格ポーズを生成することができる画期的なモデルであり、手話データ処理における課題に取り組むための新たな標準を確立しています。研究者たちがPrompt2Signデータセットに基づいて開発したこのモデルは、手話生成に革新をもたらす可能性があります。