
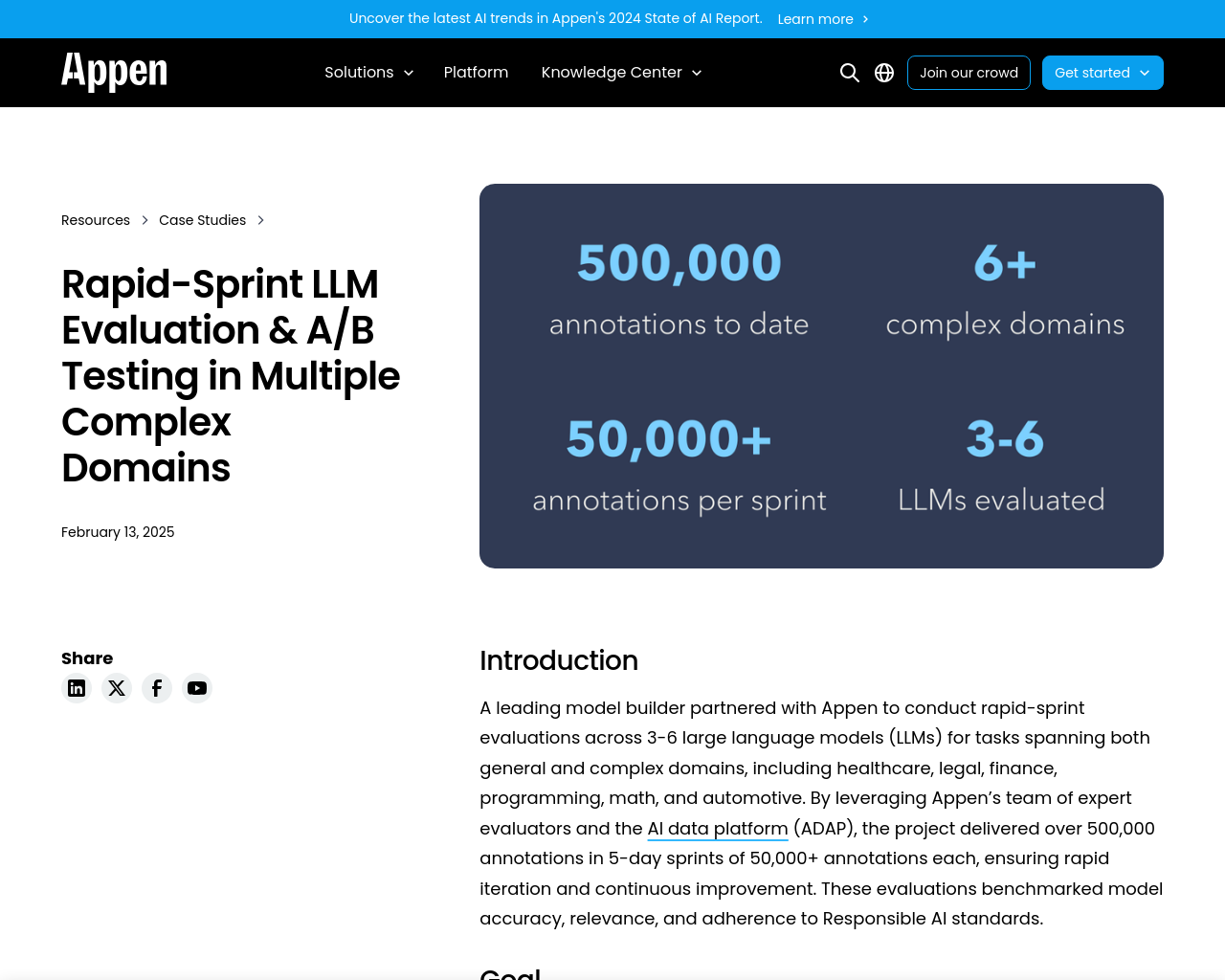
- Appenと主要なモデルビルダーが連携し、医療、法律、金融、プログラミング、数学、自動車など幅広い領域にわたるタスクのために3-6の大規模言語モデル(LLMs)の迅速な評価を実施
- プロジェクトは、Appenの専門評価者チームとAIデータプラットフォーム(ADAP)を活用し、5日間のスプリントで50,000以上の注釈を含む500,000以上の注釈を提供
- 評価はモデルの精度、関連性、および責任あるAI基準への遵守をベンチマーク化
- プロジェクトの主な目的は、多様な産業にわたる複数のLLMsのパフォーマンスを評価および改善すること
- 構造化された評価とA/Bテストを実施し、モデルの効果的性能について正確な洞察を提供
- Appenは、複数のLLMsと領域にわたる迅速なスプリント評価の管理においていくつかの主要な課題に取り組むために構造化された評価フレームワークを採用
- 迅速なスプリント評価とA/Bテストフレームワークは、モデルビルダーに対して、多様な領域にわたるLLMのパフォーマンスを最適化するための具体的な洞察を提供
- 専門家の評価、スケーラブルなA/Bテスト、AI駆動のワークフロー管理を活用することで、Appenはクライアントに、多様な産業にわたるLLMのパフォーマンスを向上させ、ビジネスニーズと責任あるAI原則との整合性を確保する力を与えた
この記事は、Appenと主要モデルビルダーが連携して、多様な産業にわたる複数の大規模言語モデル(LLMs)のパフォーマンスを評価および改善するプロジェクトについて述べています。Appenの専門評価者チームとAIデータプラットフォーム(ADAP)を活用し、迅速なスプリント評価とA/Bテストを通じてモデルの精度や関連性を向上させ、責任あるAI基準に準拠することを目指しています。
元記事: https://www.appen.com/case-studies/llm-evaluation-complex-domains