
- DeepSeekが主張する大規模言語モデル(LLM)の訓練速度と効率は、シリコンバレーにとって現実的な課題になっている。
- 中国のAlibabaが新たなモデルQwen 2.5 Maxを発表し、DeepSeekのV3を上回ると主張。
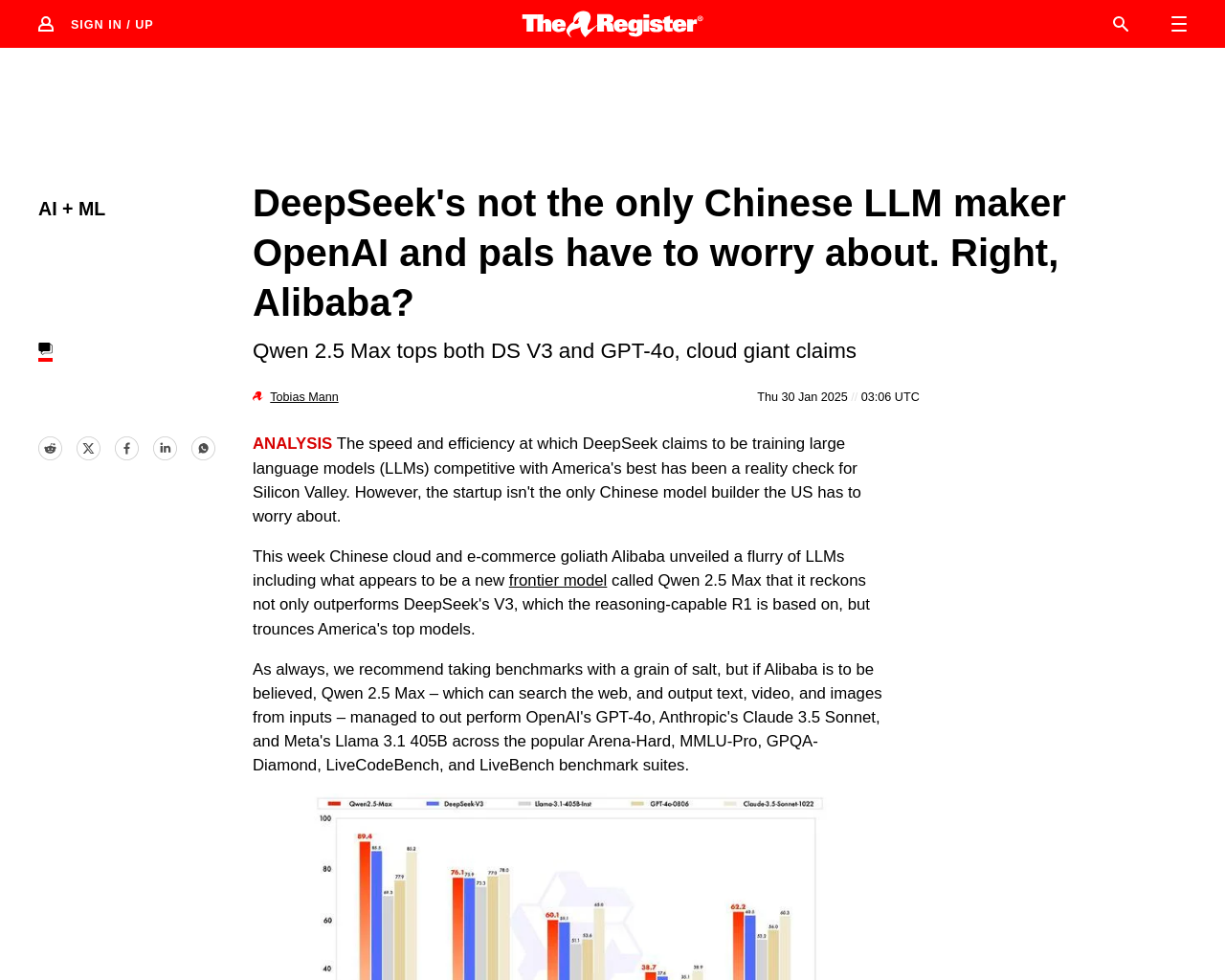
- AlibabaのQwen 2.5 Maxは、OpenAIのGPT-4o、AnthropicのClaude 3.5 Sonnet、MetaのLlama 3.1 405Bを超える性能を示す。
- AlibabaのQwen 2.5 Maxは、MoEモデルであり、20兆トークンのコーパスで訓練され、さらに人間のフィードバックからの教師付き微調整と強化学習によって洗練された。
- MoEモデルは、パラメータ数と実際の性能を分離するために人気があり、クエリに関連する部分のみを活性化し、スループットを犠牲にすることなくパラメータ数を増やすことが可能。
AlibabaのQwen 2.5 Maxは、DeepSeekに対する比較を行っており、OpenAIのフラッグシップo1モデルではなくGPT-4oとの比較が行われている点に注目です。MoEモデルの使用やパラメータ数など、AI開発の進化に伴う革新的な要素が見られます。
元記事: https://www.theregister.com/2025/01/30/alibaba_qwen_ai/