
- Amazon Finance OperationsのAPおよびARアナリストは、お客様からのクエリを電子メール、ケース、内部ツール、または電話で受け取ります。
- クエリが発生すると、アナリストは主題専門家(SME)に連絡を取り、クエリに関連する標準作業手順(SOP)を含む複数のポリシードキュメントを確認する必要があります。
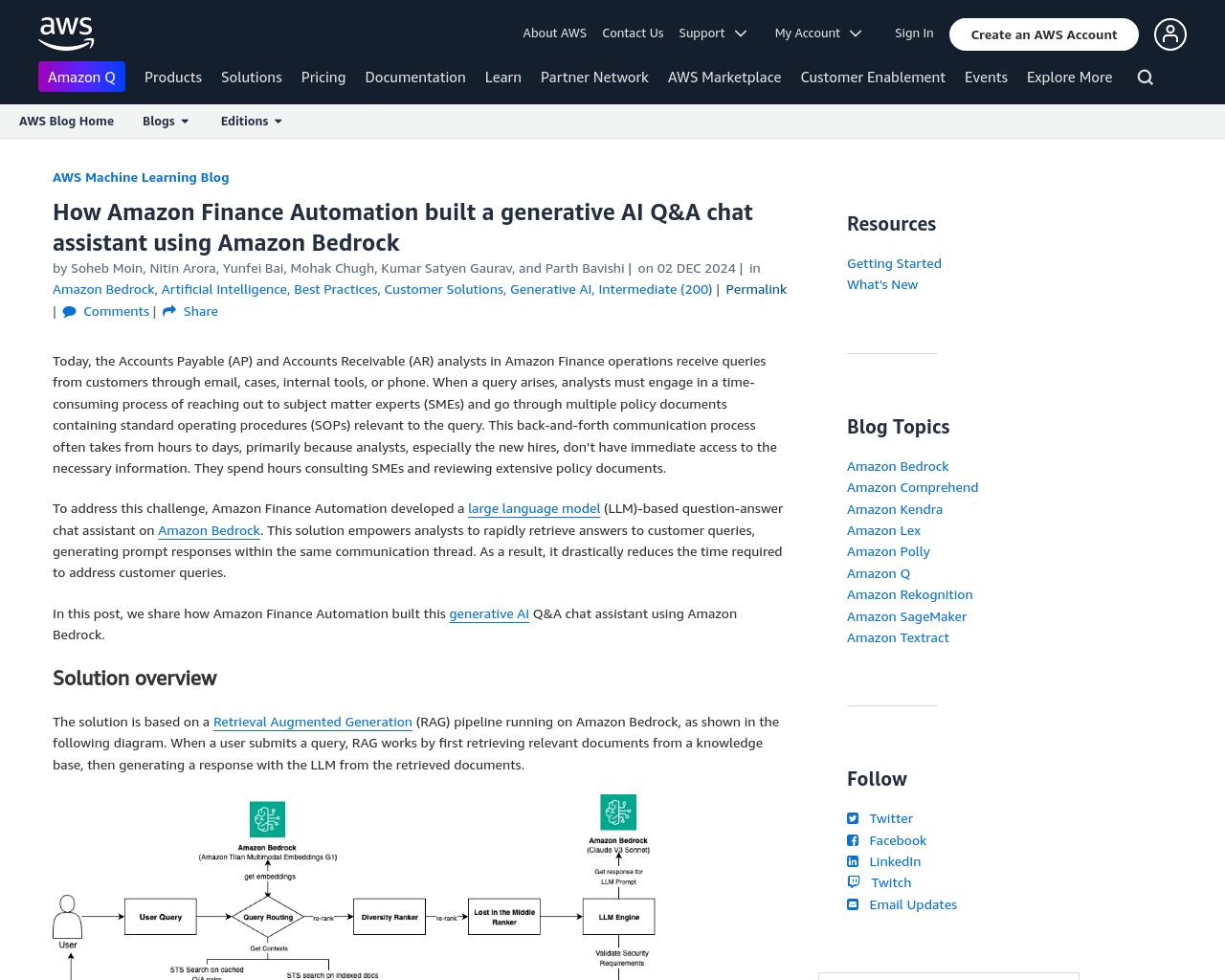
- この課題に対処するために、Amazon Finance AutomationはAmazon Bedrock上に大規模な言語モデル(LLM)ベースの質問応答チャットアシスタントを開発しました。
- このソリューションには、以下の主要なコンポーネントが含まれています。
- チャットアシスタントの正確性は、Amazon Finance Operationsにとって最も重要なパフォーマンスメトリクスです。
- 正確性を向上させるため、文書分割アプローチを設計し、Amazon Titan Text EmbeddingsとOpenSearch Serviceを使用しました。
- プロンプトエンジニアリングのアプローチを実装することで、RAGの正確性を向上させ、メタプロンプトを使用してさらにRAGの正確性を向上させました。
- 最終的に、Amazon Titan Text Embeddings G1モデルを採用することで、全体の正確性を76%から86%に向上させました。
私の考え:
Amazon Finance Automationが開発したRAGパイプラインとLLMを使用した生成的AI Q&Aチャットアシスタントは、劇的な正確性の向上を達成しました。自動化されたパフォーマンス評価の採用や文書分割アプローチの設計など、技術的な改善を重ねてきたことが成果をもたらしたと感じます。