
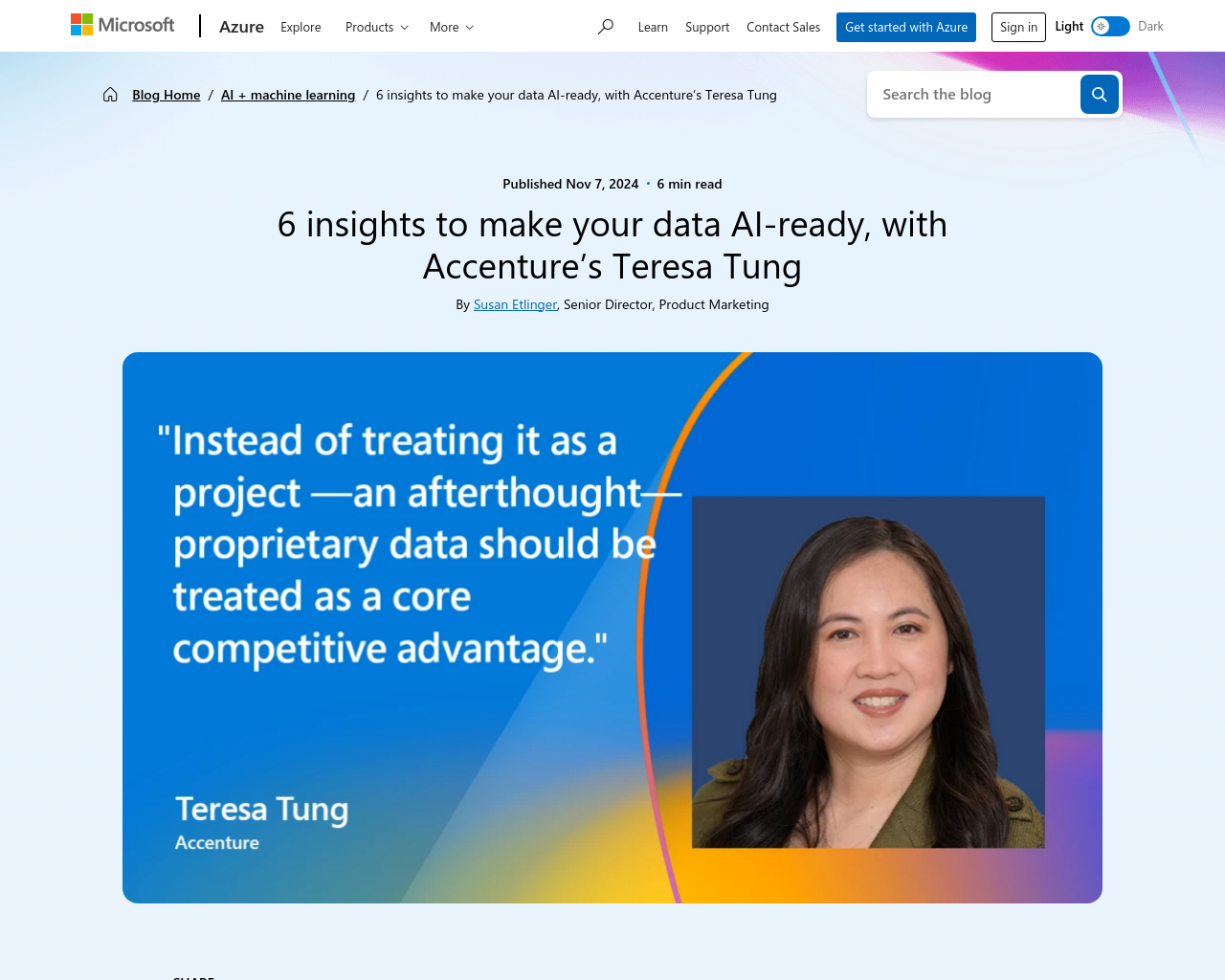
- プロプライエタリデータの品質とアクセシビリティが組織の革新の鍵である
- プロプライエタリデータは競争上の優位性として扱われるべき
- ジェネラティブAIモデルはインターネット規模のデータに事前トレーニングされているが、独自のデータがないと他社と同じ結果を提供する
- 非構造データはジェネラティブAIにおいて重要であり、合成データはデータの欠落を埋めるために必要
- 知識の蒸留やコンテキストの重要性など、データの意味や重要性が明確になる
- ジェネラティブAIは新たな機会とリスクをもたらすが、データの活用とセキュリティの再考が必要
- データの活用とプロセスへの適用により、ジェネラティブAIはデータのサプライチェーンを構築し、業務を変革する
私の考え:
この記事では、プロプライエタリデータの重要性やジェネラティブAIの活用方法が詳細に説明されています。データの品質とアクセシビリティが革新の鍵であること、非構造データや合成データの重要性、コンテキストの意味、ジェネラティブAIのリスクなどが強調されています。データを活用することで、データサプライチェーンがよりダイナミックになり、業務プロセスが加速されることが期待されます。AIを活用するためには、組織がデジタルコアを整備し、データの品質やセキュリティに注力する必要があると感じました。