
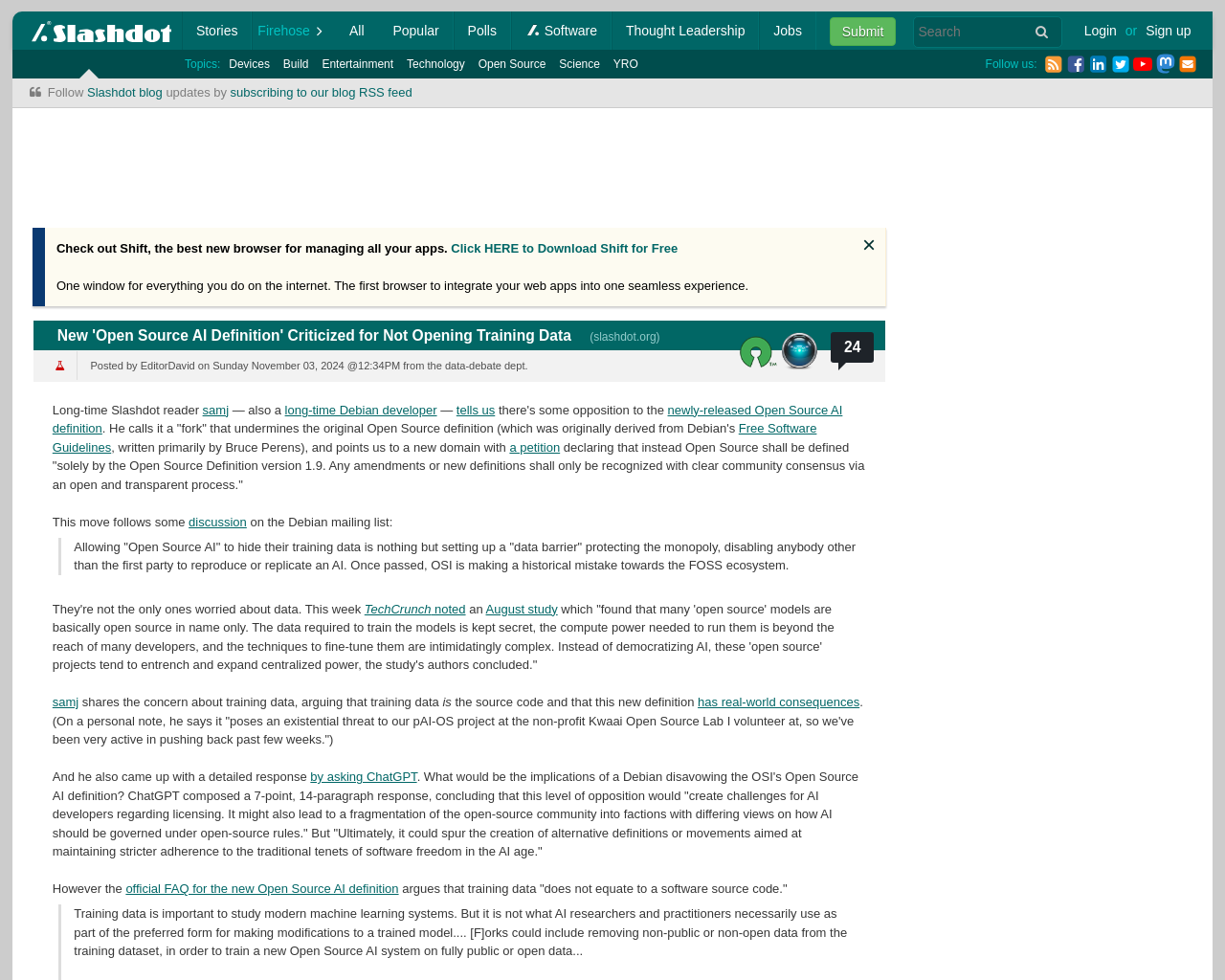
- AIモデルの作成と使用に必要な主要なコンポーネント:トレーニングデータ、前処理とデータパイプライン、トレーニング構成、トレーニングスクリプト、モデルチェックポイント、ベースモデル(適用される場合)、ファインチューニング/特殊トレーニング、トレーニングされたモデル、推論コード、デプロイメントパイプライン、評価およびテストメトリクス、ポストプロセッシング。
- AI作成の最も論争のある側面はトレーニングデータであり、それに続いて検閲が行われる可能性がある。
- OpenAIは完全にオープンではないと感じられる。
- 大部分は許可なく非合法にスクレイプされており、多くはクソだと述べられている。
- 多くの公開ウェブサイトのコンテンツは「全著作権保護」のライセンスの下にある。
- 訓練データを公開したがらない理由は、訓練データの再共有を制限する法律があるため。
私の考え:
訓練データの取り扱いはAI開発において重要であり、その取得や利用には法的な問題が存在することが明らかです。オープンソースAIにおけるデータ公開の難しさやライセンスに関する議論が続いているようです。