
要約:
- OpenAIは最新モデルChatGPT-o1を発表。人間らしい推論能力とAIの新基準設定に称賛。
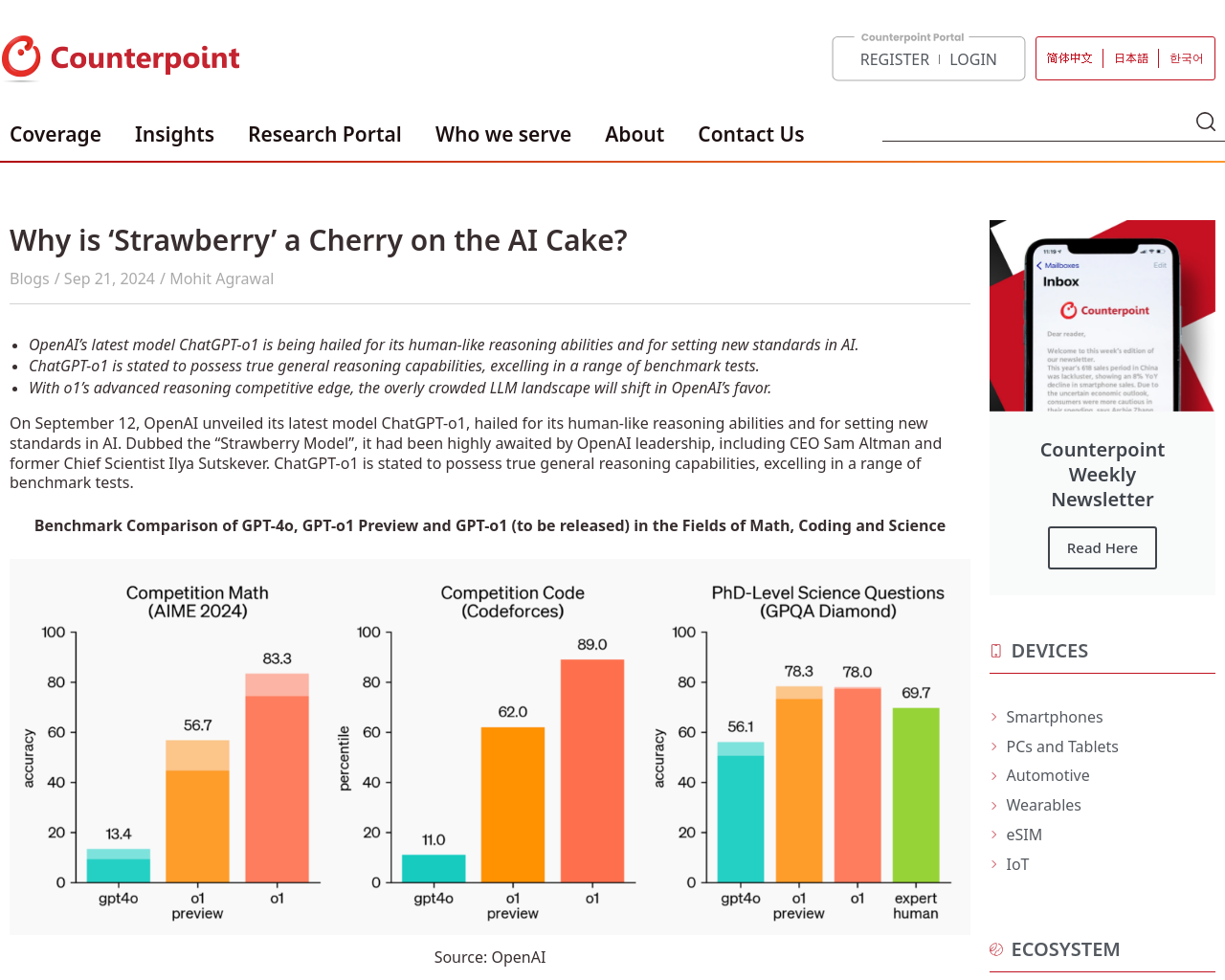
- ChatGPT-o1は真の一般的推論能力を持ち、さまざまな基準テストで優れている。
- GPT-4oと比較したo1は、数学、コーディング、科学のベンチマークテストで傑出した結果を達成。
- 強化学習は報酬と結果のサイクルでAIを訓練し、データフライホイールを生み出す。
- LLMの課題の1つは幻覚傾向であり、OpenAIのo1モデルは構造化された推論プロセスを採用。
- o1の推論時間の比較チャートでは、o1の推論能力が大幅に向上。
- OpenAI o1はGPT-4oと比較してコーディングエージェントの性能を向上させる。
感想:
OpenAIのChatGPT-o1は、真の一般的推論能力を持つ驚くべきモデルであり、数学や科学のベンチマークテストで高い成績を収めることが示されました。強化学習を通じてAIを訓練し、推論時間を重視することで、o1は従来のモデルよりも優れた推論能力を持つことが示されています。幻覚傾向への対処法や構造化された推論プロセスの採用など、o1の革新的なアプローチは、AIの将来に期待を抱かせます。
元記事: https://www.counterpointresearch.com/insights/why-is-strawberry-a-cherry-on-the-ai-cake/