
要約:
- 2022年にOpenAIがChatGPTをリリースし、人間らしいテキストを生成するAIチャットボットが公になった。
- 生成AIの向上のために、OpenAIや他の開発者は高品質のトレーニングデータが必要。
- ウェブから必要なデータを得ることは困難で、ノイズが多い。
- AI開発者は、人間が作成した代わりにAIが生成した「合成データ」で問題を解決しようとしている。
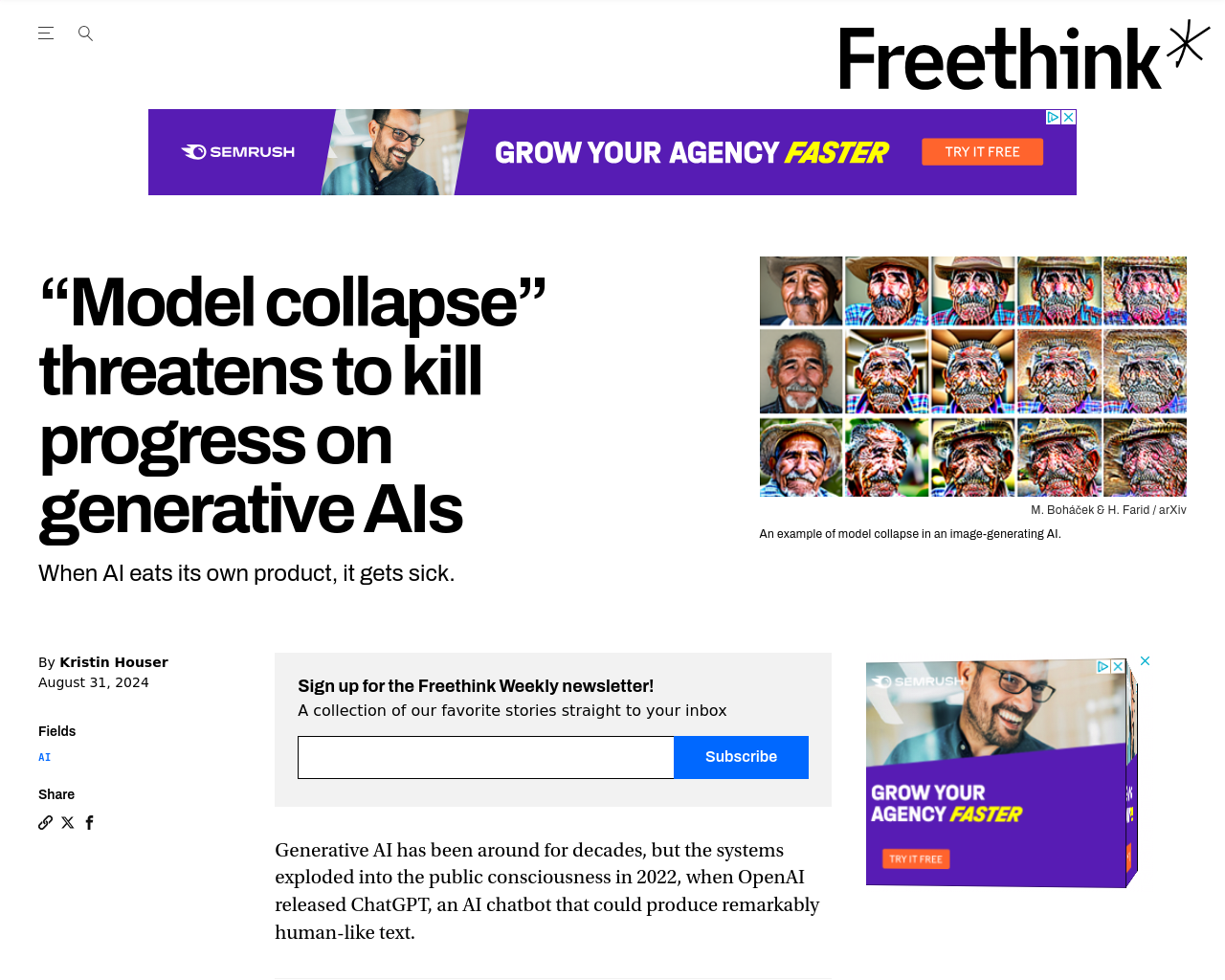
- 合成データによる訓練はモデルの崩壊を招き、モデルが意味不明なものを生成する可能性がある。
- 合成データを使用することで、バイアスのある結果を生み出す可能性がある。
- AI開発者はこれらの問題の解決策を模索している。
感想:
合成データを使用することで、AIの訓練や生成に関する重要な課題が浮き彫りになりました。モデルの崩壊やバイアスの問題は深刻であり、解決策を見つける必要があります。人間や他のAIによるデータの評価や規制、高品質なトレーニングデータの入手など、様々なアプローチが提案されていますが、課題は複雑であり、迅速な対応が求められます。
元記事: https://www.freethink.com/robots-ai/model-collapse-synthetic-data