
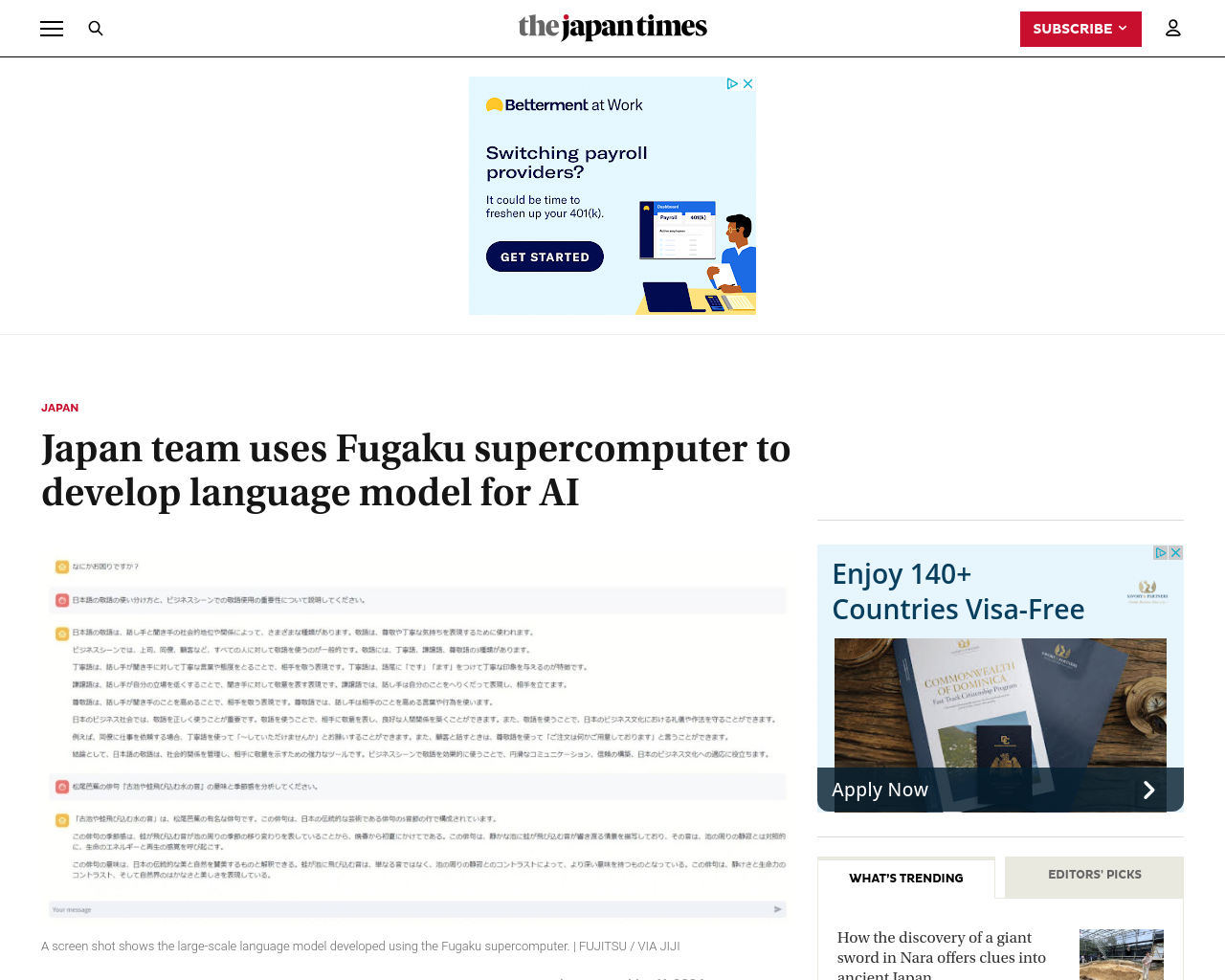
東京工業大学、富士通などの研究チームは、日本のスーパーコンピュータ「富岳」を利用して、生成型人工知能の基盤となる大規模言語モデルを開発したと発表した。
金曜日に公開された富岳-LLMモデルは、全トレーニングデータの60%を占める日本語データで徹底的にトレーニングされており、国内のニーズに合わせた生成AIの研究につながることが期待されている。
2023年5月、東北大学、名古屋大学、理化学研究所、サイバーエージェント、コトバテクノロジーズの研究者も加わり、富士通と理化学研究所が共同開発したスーパーコンピューターを活用したプロジェクトを開始した。
誤報と情報過多の時代にあって、質の高いジャーナリズムはこれまで以上に重要です。購読することで、私たちが正しいストーリーを伝えるのを手伝っていただけます。
元記事: https://www.japantimes.co.jp/news/2024/05/11/japan/ai-fugaku-language-model-japanese/