
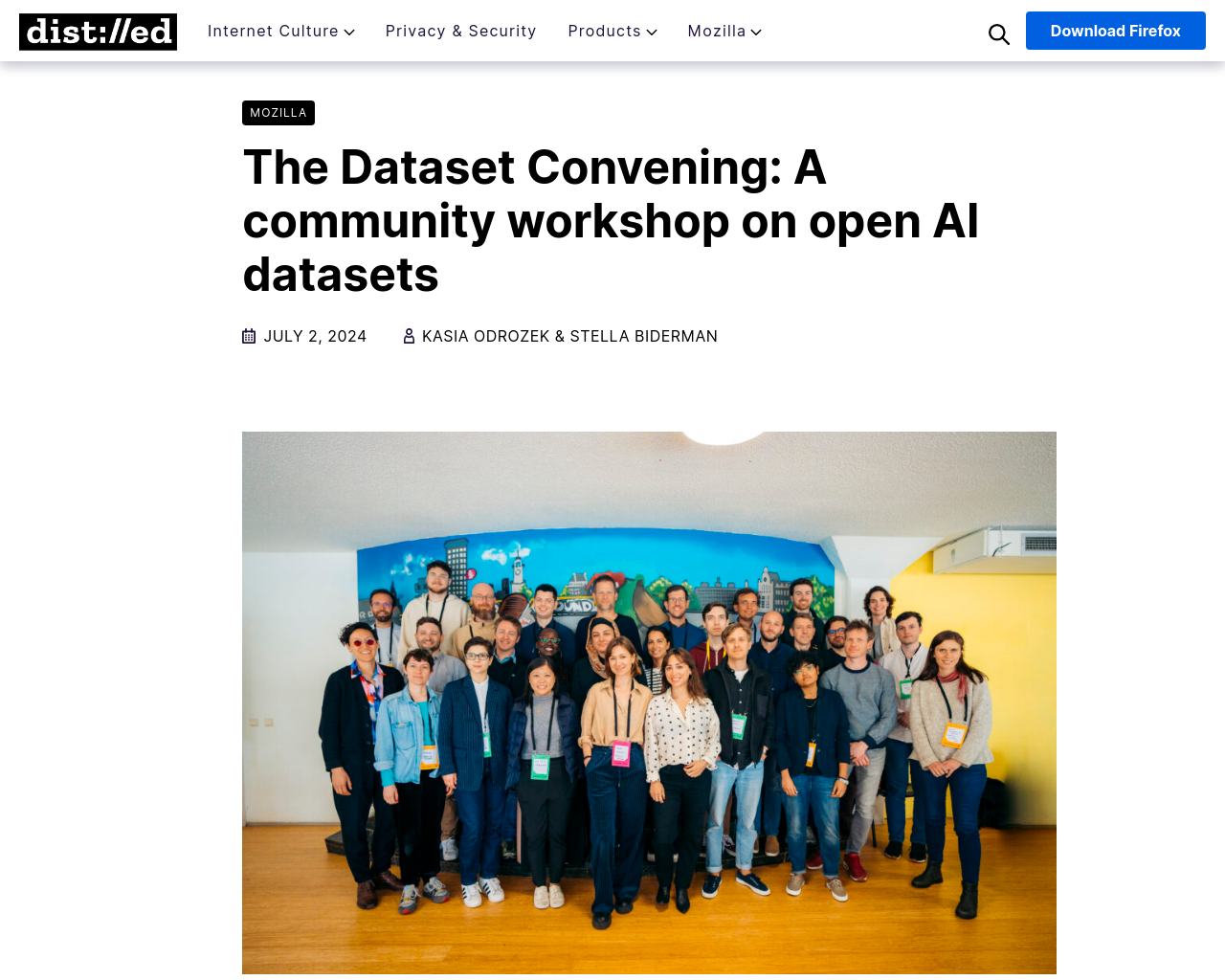
- モジラとEleutherAIは、30人の主要なオープンソースAIスタートアップ、非営利AI研究所、市民社会組織の学者と実務者を集め、オープンアクセスかつ公開ライセンス付きのLLMトレーニングデータセットの作成について議論
- 競争の増加と法的リスクのため、現在は事前トレーニングデータセットを共有することがほとんどなくなったが、オープンアクセスのデータは競争、イノベーション、透明性を促進し、法的立場の明確化と検証に立ち向かう能力を提供
- オープンLLM開発者たちは、より透明で責任あるAIの進歩のための設計図を提供するLLMトレーニングデータセットを作成、イベントでは「Common Pile」のリリースと共に技術ブリーフィングと公開協議の招待を行った
- 議論のハイライトとして、オープンアクセスおよび公開ライセンス付きデータセットの推進に関する規範的および技術的な推奨事項とベストプラクティスを開発するために、オープンデータセット構築者の経験を取り入れた
私の考え:オープンアクセスのデータは、AI開発者が互いの成果を活用し、競争、イノベーション、透明性を促進する重要な公共財であると考えられる。オープンなアプローチは、AIコミュニティ全体の成長と強化に役立つ可能性があります。
元記事: https://blog.mozilla.org/en/mozilla/dataset-convening/