
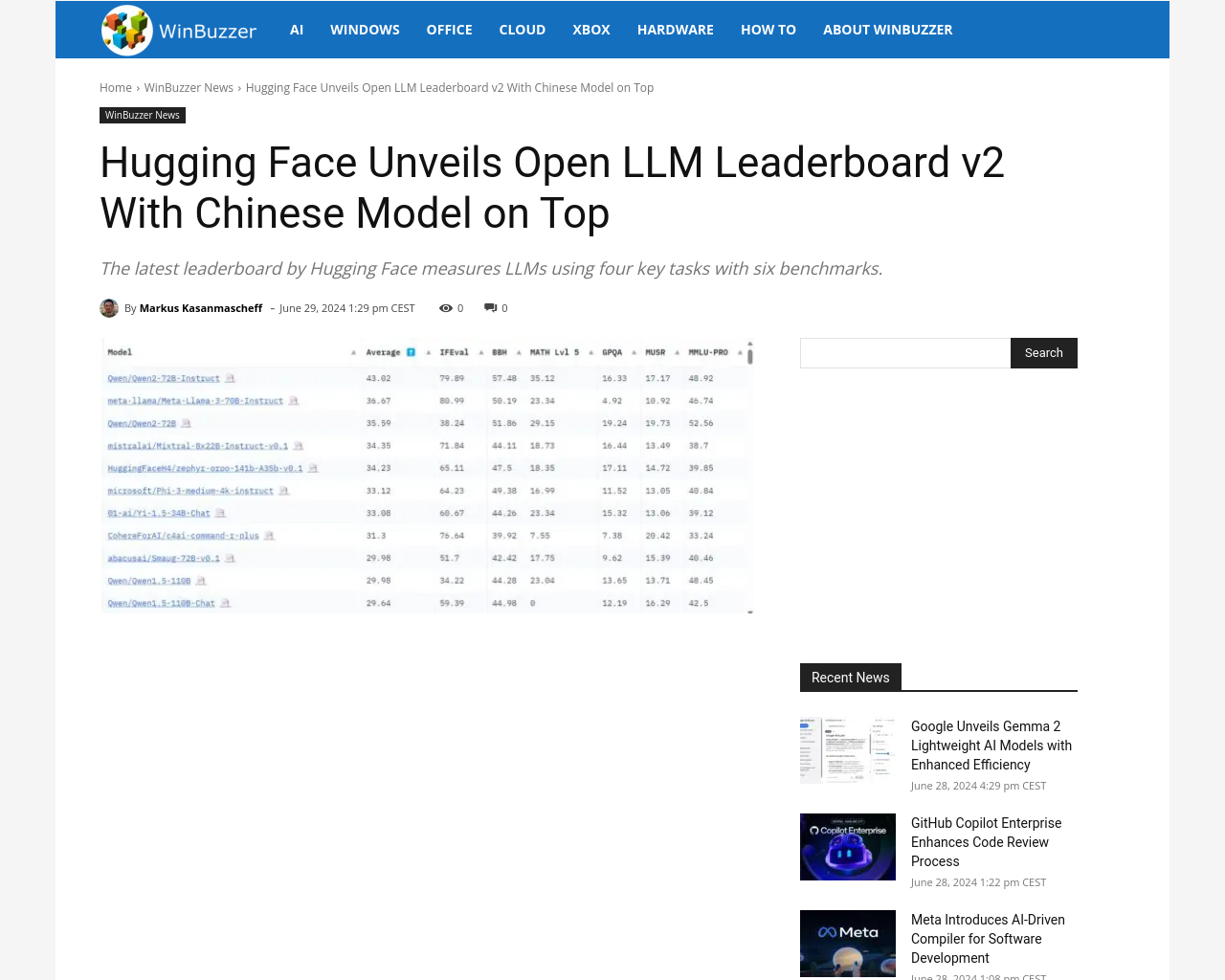
要約:
- Hugging Faceの最新のリーダーボードは、4つの主要タスクと6つのベンチマークを使用してLLMsを評価しています。
- AlibabaのQwenモデルはトップ10のうち3つの位置を獲得し、中国のAIモデルの優れたパフォーマンスを示しています。
- 評価は、知識評価、拡張コンテキストでの推論、複雑な数学、指示の従属など、4つの主要タスクを使用しています。
- 評価には、科学的問いに答えることから真実の回答を生成し、高校レベルの数学問題を解くなど、さまざまなベンチマークが含まれています。
感想:
新しいリーダーボードは、複数のタスクを含む豊富なベンチマークを使用してLLMsを評価する点で非常に興味深いです。特に、AlibabaのQwenモデルの成功は注目に値します。多様な評価基準を取り入れることで、モデルの実世界での有用性を向上させることが重要であることが強調されています。Hugging Faceの週次更新と詳細な分析により、最新のパフォーマンスデータが反映され、モデルの強みと弱みが明らかになります。