
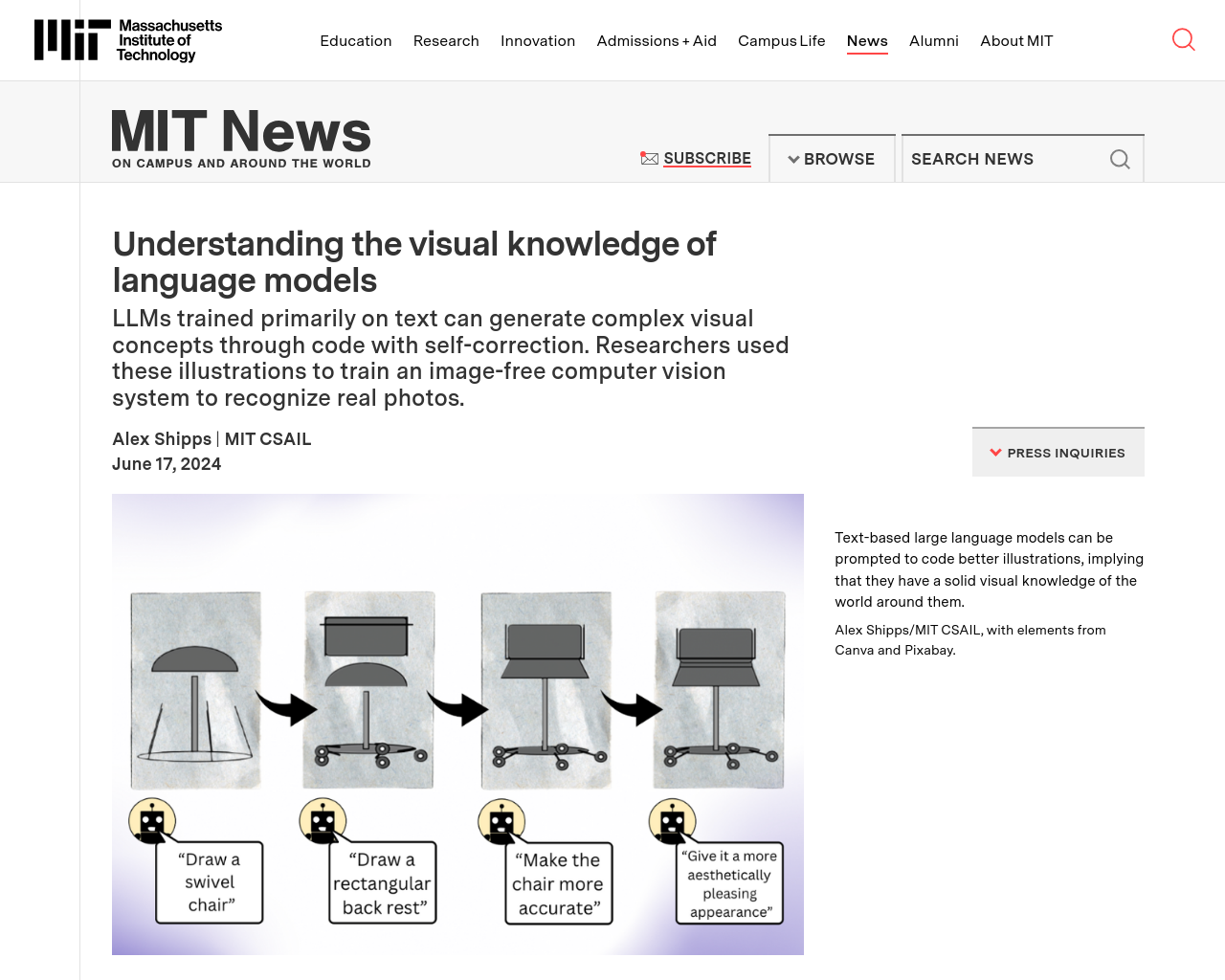
- 言語モデルは、テキストのみで訓練されたが視覚的世界の理解力がある
- CSAILチームは、言語モデルの視覚的知識を評価する「Vision Checkup」を構築
- 言語モデルは、コード生成を通じて多くの知識を持っており、視覚的効果を生成できる
- CSAILチームは、言語モデルの視覚的知識と他のAIツールの芸術的能力を組み合わせることを提案
- 言語モデルは、同じ概念を描画することができるが、誤って識別することもある
- CSAILチームは、この手法がAIモデルがコンピュータビジョンシステムをどれだけうまく訓練できるかの基準になる可能性があると考えている
CSAILチームの研究では、言語モデルが視覚的知識を持っていることが示されました。言語モデルは、テキストのみで訓練されているにも関わらず、複雑なシーンやオブジェクトを生成することができることがわかりました。また、この視覚的知識を利用して、コンピュータビジョンシステムを訓練する可能性や、他のAIツールと組み合わせることで芸術的な能力を向上させることが提案されています。
元記事: https://news.mit.edu/2024/understanding-visual-knowledge-language-models-0617