
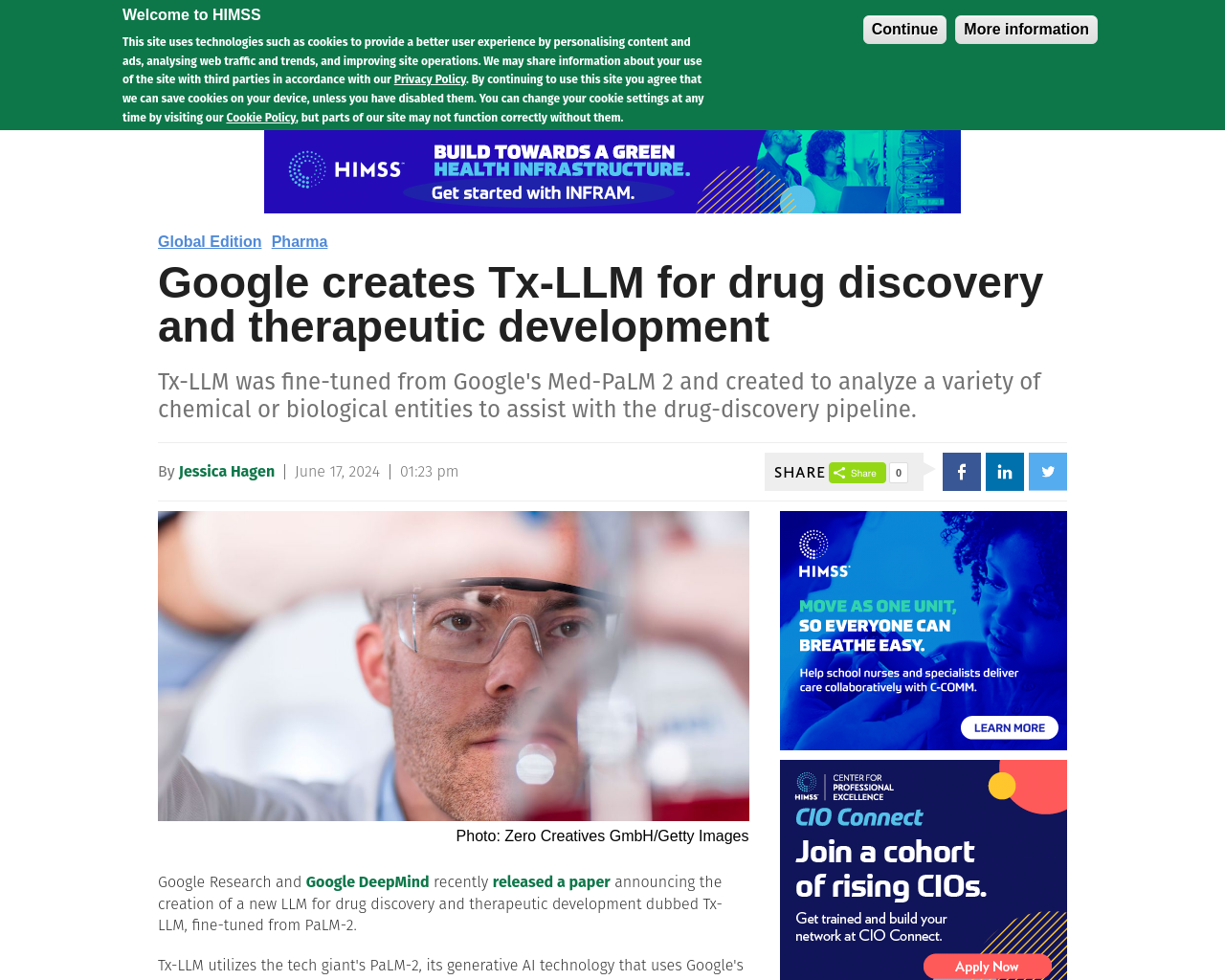
- Google ResearchとGoogle DeepMindは、新しいLMMであるTx-LLMを発表
- Tx-LLMは、PaLM-2をベースに調整された薬剤探索と治療開発に特化
- Tx-LLMは、709のデータセットを使用して訓練され、効果や安全性の評価、ターゲットの予測、製造の容易さなど66のタスクに対応
- SMILESは、分子や反応を表す印刷可能な文字を使用する簡略化された分子入力ラインエントリーシステム
- TxTは、自由なテキスト指示とSMILES文字列などの小分子表現を交互に配置して構築される
- Tx-LLMは、薬剤探索と治療開発に関連する分類、回帰、生成タスクを解決するためにTxTを使って微調整された
- 研究者は、異なる薬剤の種類を含むデータセットのトレーニングが、分子データセットのパフォーマンス向上につながる正の転送の証拠を発見
- Tx-LLMは66のタスクのうち43でSOTAモデルの上または近くを達成し、22のタスクでSOTAモデルを上回った
この技術記事では、Google ResearchとGoogle DeepMindが新しい薬剤探索と治療開発向けのLMMであるTx-LLMを発表しました。Tx-LLMはPaLM-2をベースに調整され、様々な薬剤探索の段階における66のタスクを対象とするために訓練されました。特に、Tx-LLMは分子データセットのパフォーマンス向上につながる正の転送の証拠を見出しました。このTx-LLMの提案は、治療開発パイプラインの複数のステップに対して単一のモデルをクエリすることを可能にし、期待されています。