
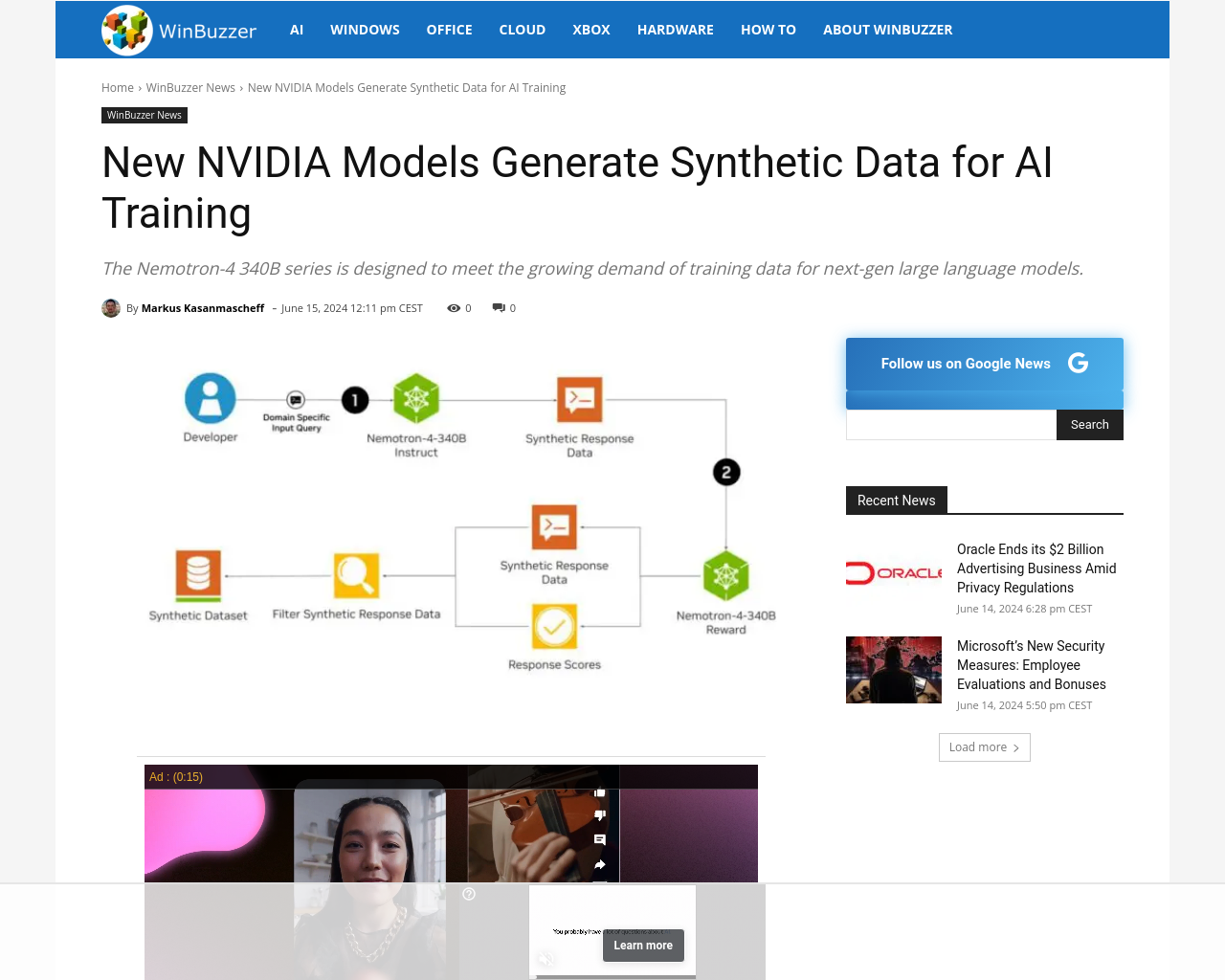
要約:
- NVIDIAがNemotron-4 340Bシリーズを発表し、大規模言語モデルのトレーニングデータ需要に対応。
- Nemotron-4 340Bシリーズには、ベースモデル、インストラクトモデル、リワードモデルが含まれる。
- Nemotron-4 340Bモデルは、NVIDIA NeMoおよびTensorRT-LLMとの統合を可能にし、Hugging Faceやai.nvidia.comからダウンロード可能。
- 高品質なトレーニングデータ不足に対処するため、Nemotron-4 340Bはスケーラブルな合成データ生成を提供。
- Nemotron-4 340Bのモデルは、高品質な合成データを生成し、AIのトレーニングを改善。
- NVIDIA NeMoとTensorRT-LLMは、モデルの効率を最適化するために重要。
- NeMoおよびTensorRT-LLMは、NVIDIA AI Enterpriseソフトウェアプラットフォームを介してアクセス可能。
考察:
大規模言語モデルのトレーニングデータ不足に対するニーズは高まっており、NVIDIAの取り組みはその需要に応えるものとなっている。Nemotron-4 340Bシリーズのモデルは、合成データ生成において高い効果性を示し、特定領域におけるカスタム言語モデルの性能向上に寄与している点が注目される。また、NVIDIA NeMoとTensorRT-LLMの統合によって、モデルの効率化が図られ、安全性やセキュリティを重視する企業にとっても支援が提供されている点が重要である。