
- 多様な研究を促進する環境を作成
- 基礎研究と応用研究を通じてコンピュータサイエンスの進歩を推進
- 数十億人が利用する技術に影響を与える機会を持つ
- 広範な研究コミュニティとのオープンソースプロジェクト
- Google製品への展開
- アイデアを共有し、コンピュータサイエンスの分野を前進させるために研究成果を公開
- 協力的なエコシステム構築を目指して製品、ツール、データセットを提供
- 幅広いプログラミングを通じて次世代の研究者を支援
- 大学教員との意義深い関与を通じて学術研究コミュニティに参加
- イベントを通じて広範な研究コミュニティとのつながりを築く
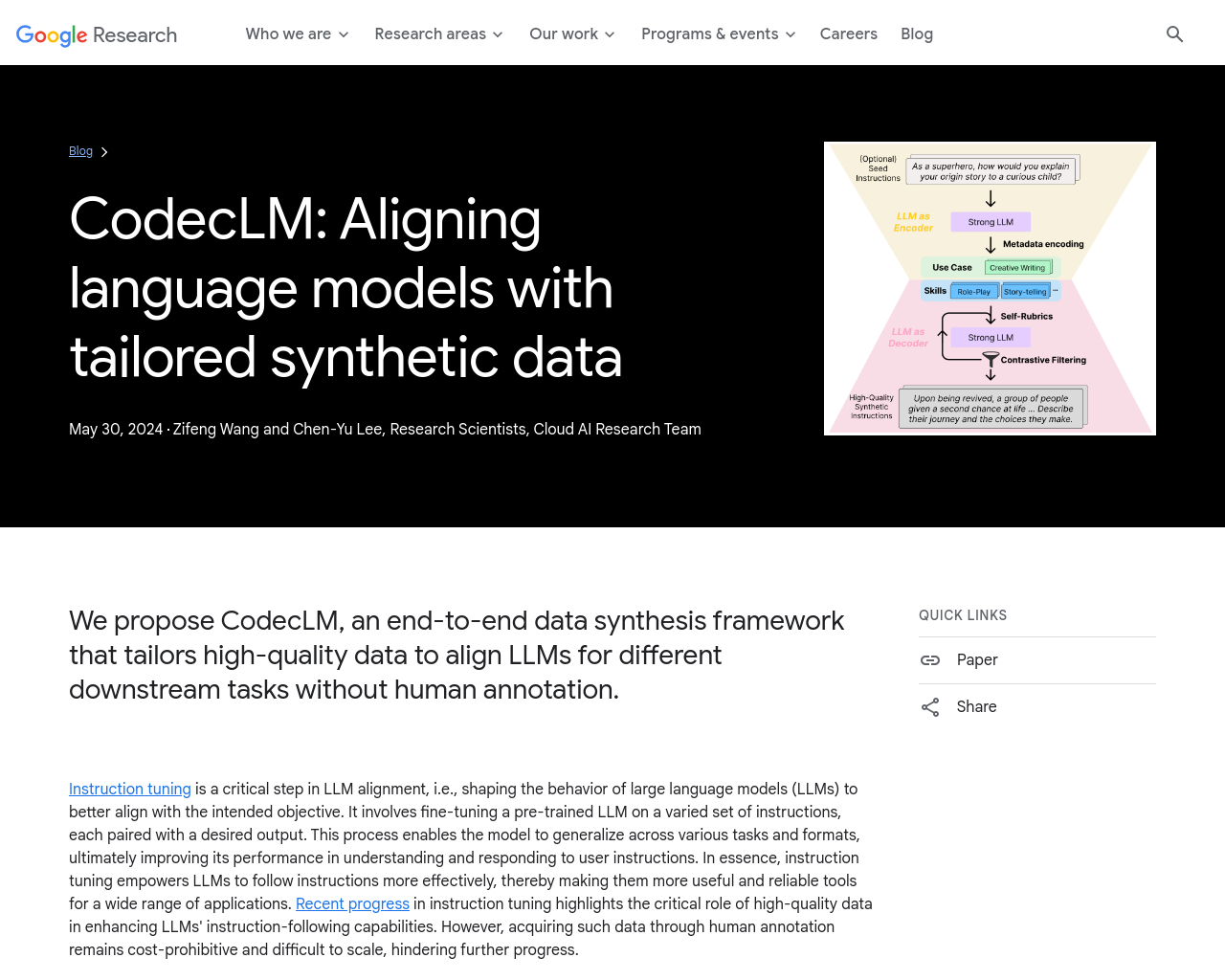
「CodecLM: Aligning Language Models with Tailored Synthetic Data」は、特定の下流タスクのためにLLMを整列させるために調整された高品質のデータをシステム的に生成する新しいフレームワークである。
CodecLMのコアアイデアは、異なる下流タスク向けに合成データをカスタマイズし、それを調整するためにLLMを微調整することである。この目標を達成するために、合成データの分布が実際の下流データのそれと類似していることと、合成データの品質が十分に高いことを確認する必要がある。
元記事: https://research.google/blog/codeclm-aligning-language-models-with-tailored-synthetic-data/